🟥🟩🟦
- COMPILATION
- BUFFER & STREAMS
- MEMORY (UNDER THE HOOD)
- FAULTS
- STRINGS
- ARRAYS
- FUNCTIONS
- POINTERS & REFERENCES)
- Compiler's Optimizations
- OBJECT-ORIENTED PROGRAMMING
- STATIC (Variables, Methods and Objects)
- ABSTRACTION
- INHERITANCE
- INHERITANCE -> UPCASTING & DOWNCASTING
- POLYMORPHISM
- Virtual Function & Runtime Polymorphism (Function Overriding)
- EXCEPTION HANDLING
- GENERIC PROGRMMING
- DYNAMIC MEMORY ALLOCATION}
- EXTRAS (Typedef, Type Inferences, decltype, exit() & _ Exit(), Command Line Arguments, Variadic function template, Local classes, Nested class and Range based for loop)
🟥🟩🟦
- The prerequisites to the repo is basic c++ itself because the repo contains-: 1. Lesser known cpp facts. 2. Tips for your cpp code and 3. In-depth cpp concepts.
- If you like it do click on the star (present at the top right corner of the screen) and share it with your friends.
- Feel free to put up a Pull request and to fork the repo.
🟥🟩🟦
Programmer writes the source code in plain text, often in an IDE (Integrated Development Environment). The program is then compiled (converted) to a language that the computer can understand, and run as a program. This is normally a two step process that consists of: 1. Pulling in any specified header files and creating Assembly (or object) code native to the processor. 2. Using a linker program to pull in any other object or library files required, to finally output machine code (1's and 0's). This resulting code is usually known as a binary or executable file. The program can then be run (or executed) on the computer.

- Defined Terms-:
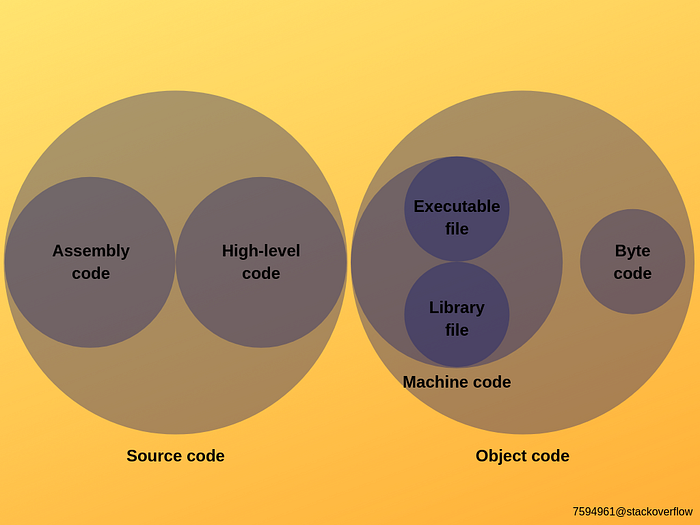
- Source Code-: Input to a compiler or other code translator. Source code is normally generated by humans (and thus hopefully able to be read and modified by humans).
- Assembly Code-: is plain-text and (somewhat) human read-able source code that mostly has a direct 1:1 analog with machine instructions. i.e. a low-level programming language code that requires software called an assembler to convert it into machine code. Hence it has strong correspondence between the program’s statements and the architecture’s machine code instructions.
- Object code-: is code generated by a assembler, consisting of machine code combined with additional metadata that will enable a linker to assemble it with other object code modules into executable machine code. i.e. Object code is a portion of machine code that hasn’t yet been linked into a complete program. It may also contain placeholders or offsets not found in the machine code of a completed program. The linker will use these placeholders and offsets to connect everything together.
- Machine Code/Executable File-: The product of the linking process. They are machine code which can be directly executed by the CPU without further translation.
🟥🟩🟦
Buffer-: A region of storage used to hold data. IO facilities often store input or output in a buffer and read or write the buffer independently from actions in the program. Using a buffer allows the operating system to combine several output operations from our program into a single system-level write. Output buffers can be explicitly flushed to force the buffer to be written. By default, reading cin flushes cout; cout is also flushed when the program ends normally. By default, All output buffers are flushed as part of the return from main.
Note-: cout is an object of ostream class and cin is an object of istream class.
Manipulator-: Object, such as std::endl, that when read or written “manipulates” the stream itself. Clearing output buffer-:
- endl-: It is a manipulator. Writing endl has the effect of ending the current line and flushing the buffer associated with that device. Flushing the buffer ensures that all the output the program has generated so far is actually written to the output stream, rather than sitting in memory waiting to be written.
- flush-: writes the output, then flushes the buffer and adds no data (contrary to which endl, adds a new line).
- ends-: writes the output adds a null, then flushes the buffer.
e.g. If three cout statements prints 1,2,3 respectively, without any cin statement in between or any manipulator used would print the three numbers on the same line but using endl will write the output of each cout statement on a seperate new line.
Disadvantage-: Flushing of buffers is an Operating System task. Each time the buffer is flushed, a request has to be made to the OS and these requests are comparatively expensive. Furthermore, we don’t really need to flush the buffer every time we write something to the stream, since the buffers get flushed automatically when they get full. Solution-: Writing ‘\n’ characters directly to the stream is more efficient since it doesn’t force a flush like std::endl.
Clearing input buffer-: In case of C++, after encountering“cin” statement, we require to input a character array or a string , we require to clear the input buffer or else the desired input is occupied by buffer of previous variable, not by the desired container. Solution-: Typing “cin>>ws” after “cin” statement tells the compiler to ignore buffer and also to discard all the whitespaces before the actual content of string or character array.
🟥🟩🟦
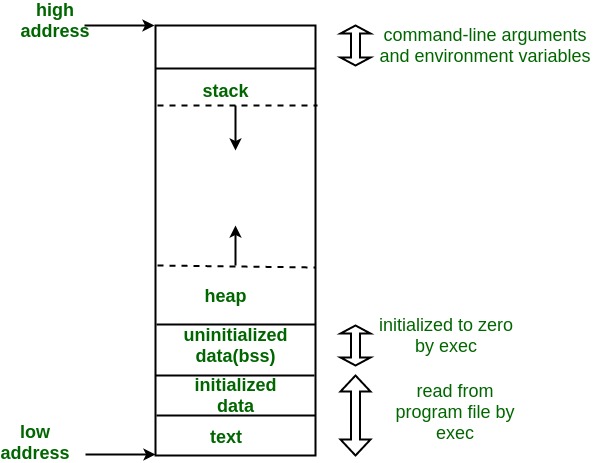
A typical memory representation of C++ program consists of following sections.
- Text segment (Code segment) -: Contains the compiled Machine code instructions.
- Initialized data segment (Data segment) -: Initialized global and local static variables.
- Uninitialized data segment (Block Started by Symbol (BSS) segment)-: Uninitialized or zero-initialized variables and constants.
- Heap (Free store) -: Used for Dynamic Memory allocation. In C++ managed by new and delete.
- Unallocated-: Free area, available to be utilised for growth by heap or stack.
- Stack -: Used for local variables and passing arguments to a functions, along with return address of the next instruction to be executed when the function call is over. The stack is comprised of a number of Stack Frames, with each frame representing a function call. The size of the stack increases in proportion to the number of functions called, and then shrinks upon return of a completed function.
- OS and the BIOS level -: For Environment variables and command line arguments.

#include <stdio.h>
void firstFunc() ;
void secondFunc() ;
int main() {
firstFunc() ;
return 0 ;
}
void firstFunc() {
int myInt = 17 ;
secondFunc() ;
}
void secondFunc() {
int yourInt = 42 ;
char myChar = 'd' ;
}

- Note-: Each thread gets a stack, while there's typically only one heap for the application (although it isn't uncommon to have multiple heaps for different types of allocation).
- In a stack, the allocation and deallocation is automatically done by whereas, in heap, it needs to be done by the programmer manually.
- Handling of Heap frame is costlier than handling of stack frame.
- Memory shortage problem is more likely to happen in stack whereas the main issue in heap memory is fragmentation (-: When a computer program requests blocks of memory from the computer system, the blocks are allocated in chunks. When the computer program is finished with a chunk, it can free it back to the system, making it available to later be allocated again to another or the same program. The size and the amount of time a chunk is held by a program varies. During its lifespan, a computer program can request and free many chunks of memory. When a program is started, the free memory areas are long and contiguous. Over time and with use, the long contiguous regions become fragmented into smaller and smaller contiguous areas. Eventually, it may become impossible for the program to obtain large contiguous chunks of memory. This is known as fragmentation of memory.)
- Stack frame access is easier than the heap frame as the stack have small region of memory and is cache friendly, but in case of heap frames which are dispersed throughout the memory so it causes more cache misses.
- Stack is not flexible, the memory size allotted cannot be changed whereas a heap is flexible, and the allotted memory can be altered.
- Memory leakage-: occurs in C++ when programmers allocates memory by using new keyword and forgets to deallocate the memory by using delete() function or delete[] operator.
- Instead of managing memory manually, try to use smart pointers where applicable.
- Use std::string instead of char *. The std::string class handles all memory management internally, and it’s fast and well-optimized.
- The best way to avoid memory leaks in C++ is to have as few new/delete calls at the program level as possible – ideally NONE. Anything that requires dynamic memory should be buried inside an RAII object that releases the memory when it goes out of scope. RAII allocate memory in constructor and release it in destructor, so that memory is guaranteed to be deallocated when the variable leave the current scope.
- Note-: Memory caching (often simply referred to as caching) is a technique in which computer applications temporarily store data in a computer's main memory (i.e., random access memory, or RAM) to enable fast retrievals of that data. The RAM that is used for the temporary storage is known as the cache.
Q-N-A -:
- To what extent are they (stack & heap) controlled by the OS or language runtime? ->The OS allocates the stack for each system-level thread when the thread is created. Typically the OS is called by the language runtime to allocate the heap for the application.
- What is their scope? -> The stack is attached to a thread, so when the thread exits the stack is reclaimed. The heap is typically allocated at application startup by the runtime, and is reclaimed when the application (technical process) exits.
- What makes one faster? -> 1. The stack is faster because the access pattern makes it trivial to allocate and deallocate memory from it (a pointer/integer is simply incremented or decremented), while the heap has much more complex bookkeeping involved in allocation or deallocation. Also, each byte in the stack tends to be reused very frequently which means it tends to be mapped to the processor's cache, making it very fast. 2. Another performance hit for the heap is that the heap, being mostly a global resource, typically has to be multi-threading safe, i.e. each allocation and deallocation needs to be - typically - synchronized with "all" other heap accesses in the program. 3. While the stack is allocated by the OS when the process starts (assuming the existence of an OS), it is maintained inline by the program whereas allocating or freeing heap involves calling into OS code.
🟥🟩🟦
They are signals generated when serious program error is detected by the operating system and there is no way the program could continue to execute because of these errors.
- Core Dump or Segmentation fault (SIGSEGV) -: When a piece of code tries to perform write operation in a read only location in memory or read/write operations on a freed block of memory, it is known as core dump. Scenarios-:
- Modifying a string literal (explained later)
- Accessing an address that is freed
- Accessing out of array index bounds (explained later)
- Stack Overflow-: It’s because of recursive function gets called repeatedly which eats up all the stack memory resulting in stack overflow. Running out of memory on the stack is also a type of memory corruption. It can be resolved by having a base condition to return from the recursive function.
- Dereferencing uninitialized pointer.
- Bus Error (also known as SIGBUS and is usually signal 10) -: occur when a process is trying to access memory that the CPU cannot recognise.In other words the memory tried to access by the program is not a valid memory address. It is caused due to alignment issues with the CPU (eg. trying to read a long from an address which isn’t a multiple of 4).
- Scenarios-:
- Program instructs the CPU to read or write a specific physical memory address which is not valid / Requested physical address is unrecognized by the whole computer system.
- Unaligned access of memory (For example, if multi-byte accesses must be 16 bit-aligned, addresses (given in bytes) at 0, 2, 4, 6, and so on would be considered aligned and therefore accessible, while addresses 1, 3, 5, and so on would be considered unaligned.) The main difference between Segmentation Fault and Bus Error is that Segmentation Fault indicates an invalid access to a valid memory, while Bus Error indicates an access to an invalid address.
🟥🟩🟦
- In case of strings, >> ignores anything after whitespaces and getline() reads the whole line until it encounters a new line.
- There is a threat of array decay in case of character array. As strings are represented as objects, no array decay occurs.
- String methods-:
- getline()
- push_back()
- pop_back()
- capacity()
- length()
- resize()
- copy(“char array”, len, pos)
- Iterator functions-:
- begin()
- end()
- rbegin()
- rend()
- A stringstream associates a string object with a stream allowing you to read from the string as if it were a stream (like cin).
- Method-: operator << — add a string to the stringstream object operator >> — read something from the stringstream object e.g. Count number of words in a string
#include <bits/stdc++.h>
using namespace std;
int countWords(string str)
{
// breaking input into word using string stream
stringstream s(str); // Used for breaking words
string word; // to store individual words
int count = 0;
while (s >> word)
count++;
return count;
}
int main()
{
string s = "geeks for geeks geeks "
"contribution placements";
cout << " Number of words are: " << countWords(s);
return 0;
}
Storage for Strings in C++
Note-: When a string value is directly assigned to a pointer, in most of the compilers, it’s stored in a read-only block (generally in data segment) that is shared among functions.
e.g. char *str= = "GfG";
In the above line “GfG” is stored in a shared read-only location, but pointer str is stored in a read-write memory. You can change str to point something else but cannot change value at the address present at str i.e. str="mno" is possible but *str="nmo" is not. The former is a Segmentation Fault. (For more info jump to Faults section).
🟥🟩🟦
- There is no index out of bounds checking in C++. But doing so may cause a Buffer Overflow (-: is an anomaly where a program, while writing data to a buffer, overruns the buffer's boundary and overwrites adjacent memory locations.) and a Segmentation Fault (-: For an array int arr[] = {1,2,3,4,5} , cout<<arr[10] works fine and prints a garbage value but arr[10]=9 results in a segmentation fault because the memory beyond the buffer's boundaries is read-only memory.)
- Array name indicates the address of the first element and arrays when passed to a function are always passed as pointers (even if we use square brackets).
- Compiler uses pointer arithmetic to access array element. For example, an expression like “arr[i]” is treated as * (arr + i) by the compiler.
- Array Decay-: The loss of type and dimensions of an array is known as decay of an array.This generally occurs when we pass the array to a function by value or by pointer. If you're passing an array by value, what you're really doing is copying a pointer - a pointer to the array's first element is copied to the parameter (whose type should also be the same as array element's type). This works due to array's decaying nature; once decayed, sizeof no longer gives the complete array's size, because it essentially becomes a pointer. A typical solution to handle decay is to send the array into functions by reference (int (&p)[7]).
- “array” is a “pointer to the first element of array” but “&array” is a “pointer to whole array of 5 integers”. Since “array” is pointer to int, addition of 1 resulted in an address with increment of 4 (assuming size of int in your machine is 4 bytes). Since “&array” is pointer to array of 5 integers, addition of 1 resulted in an address with increment of 4 x 5 = 20 bytes.
#include<iostream>
using namespace std;
// Passing array by value
void aDecay(int *p)
{ cout << "Modified size of array is by "
" passing by value: ";
cout << sizeof(p) << endl;
cout << *p << endl;
cout << *(++p) << endl;
}
// Function to show that array decay happens
// even if we use pointer
void pDecay(int (*p)[7])
{ cout << "Modified size of array by "
"passing by pointer: ";
cout << sizeof(p) << endl;
cout << *p << endl;
cout << *(++p )<< endl;
}
int main()
{
int a[7] = {1, 2, 3, 4, 5, 6, 7,};
cout << "Actual size of array is: ";
cout << sizeof(a) <<endl;
aDecay(a);
pDecay(&a);
return 0;
}
- Output-:
Actual size of array is: 28
Modified size of array is by passing by value: 8
1
2
Modified size of array by passing by pointer: 8
0x7fff168bcab0
0x7fff168bcacc
🟥🟩🟦
- It is always recommended to declare a function before it is used. Example-: int max(int, int); int swap(int,int); It is not required that a function be declared before use in C/C++. If it encounters an attempt to call a function, the compiler will assume a variable argument list and that the function returns int. The reason modern compilers give warnings on an attempt to call a function before seeing a declaration is that a declaration allows the compiler to check if arguments are of the expected type. Given a declaration, the compiler can issue warnings or errors if an argument does not match the specification in the function declaration.
- In C++, both void fun() and void fun(void) are same.
- Once default value is used for an argument in function definition, all subsequent arguments to it must have default value. Example-: This is an INVALID code-: void add(int a, int b = 3, int c, int d); Because if we pass 3 values to this func like- add(2,5,6), the compiler wouldn't know if they were for a,b,c or for a,c,d.
- When the program executes the function call instruction the CPU stores the memory address of the instruction following the function call, copies the arguments of the function on the stack and finally transfers control to the specified function. The CPU then executes the function code, stores the function return value in a predefined memory location/register and returns control to the calling function. This can become overhead if the execution time of function is less than the switching time from the caller function to called function (callee). For functions that are large and/or perform complex tasks, the overhead of the function call is usually insignificant compared to the amount of time the function takes to run. However, for small, commonly-used functions, the time needed to make the function call is often a lot more than the time needed to actually execute the function’s code. This overhead occurs for small functions because execution time of small function is less than the switching time. C++ provides an inline functions to reduce the function call overhead.
- Inlining is only a request to the compiler, not a command. Compiler can ignore the request for inlining. Compiler may not perform inlining in such circumstances like:
- If a function contains a loop. (for, while, do-while)
- If a function contains static variables.
- If a function is recursive.
- If a function return type is other than void, and the return statement doesn’t exist in function body.
- If a function contains switch or goto statement.
- Disadvantage-:
- The added variables from the inlined function consumes additional registers, After in-lining function if variables number which are going to use register increases than they may create overhead on register variable resource utilization.
- Too much inlining can also reduce your instruction cache hit rate, thus reducing the speed of instruction fetch from that of cache memory to that of primary memory.
- Inline function may increase compile time overhead if someone changes the code inside the inline function then all the calling location has to be recompiled because compiler would require to replace all the code once again to reflect the changes, otherwise it will continue with old functionality.
- All the functions defined inside the class are implicitly inline.
- Macro cannot access private members of class. C++ compiler checks the argument types of inline functions and necessary conversions are performed correctly. Preprocessor macro is not capable for doing this. Macros are managed by preprocessor and inline functions are managed by C++ compiler.
- C++ compiler cannot perform inlining if the function is virtual. The reason is call to a virtual function is resolved at runtime instead of compile time. Virtual means wait until runtime and inline means during compilation, if the compiler doesn’t know which function will be called, how it can perform inlining?
- A void fun() can return another void function
- Like friend class, a friend function can be given special grant to access private and protected members. A friend function can be: a) A method of another class b) A global function
class Node {
private:
int key;
Node* next;
// Other members of Node Class
friend int LinkedList::search();
// Only search() of linkedList
// can access internal members
};
- Note-: Friendship is not mutual & Friendship is not inherited. . If a base class has a friend function, then the function doesn’t become a friend of the derived class(es).
🟥🟩🟦
- A pointer can be declared as void but a reference can never be void
- The pointer variable has n-levels/multiple levels of indirection i.e. single-pointer, double-pointer, triple-pointer. Whereas, the reference variable has only one/single level of indirection.
- Once a reference is created, it cannot be later made to reference another object; it cannot be reseated. This is often done with pointers.
- References cannot be NULL. Pointers are often made NULL to indicate that they are not pointing to any valid thing.
- A reference must be initialized when declared. There is no such restriction with pointers there are few places like the copy constructor argument where pointer cannot be used. Reference must be used to pass the argument in the copy constructor. Similarly, references must be used for overloading some operators like ++.
- A pointer has its own memory address and size on the stack whereas a reference shares the same memory address (with the original variable) but also takes up some space on the stack.
- Due to the above limitations, references in C++ cannot be used for implementing data structures like Linked List, Tree, etc. In Java, references don’t have the above restrictions and can be used to implement all data structures. References being more powerful in Java is the main reason Java doesn’t need pointers.
Types of pointers-:
- Null Pointers-: NULL Pointer is a pointer which is pointing to nothing. In case, if we don’t have address to be assigned to a pointer, then we can simply use NULL.
- Void Pointers-: Void pointer is a specific pointer type – void * – a pointer that points to some data location in storage, which doesn’t have any specific type. Void refers to the type. Basically the type of data that it points to is can be any. If we assign address of char data type to void pointer it will become char Pointer, if int data type then int pointer and so on. Any pointer type is convertible to a void pointer hence it can point to any value. Note-: void pointers cannot be dereferenced. It can however be done using typecasting the void pointer. Pointer arithmetic is not possible on pointers of void due to lack of concrete value and thus size.
#include<stdlib.h>
int main()
{
int x = 4;
float y = 5.5;
void * ptr;
ptr = &x;
// (int*)ptr - does type casting of void
// *((int*)ptr) dereferences the typecasted
printf("Integer variable is = %d", *( (int*) ptr) );
ptr = &y;
printf("\nFloat variable is= %f", *( (float*) ptr) );
return 0;
}
- Output-: Integer variable is = 4 Float variable is= 5.500000
- Dangling Pointers-: For more information jump to Dynamic Memory Allocation section
- This Pointers-: each object gets its own copy of data members and all objects share a single copy of member functions. Then now question is that if only one copy of each member function exists and is used by multiple objects, how are the proper data members are accessed and updated? The compiler supplies an implicit pointer along with the names of the functions as ‘this’. The ‘this’ pointer is passed as a hidden argument to all nonstatic member function calls and is available as a local variable within the body of all nonstatic functions. ‘this’ pointer is not available in static member functions as static member functions can be called without any object (with class name). For a class X, the type of this pointer is ‘X* ‘. Also, if a member function of X is declared as const, then the type of this pointer is ‘const X *’. Uses-:
- When local variable’s name is same as member’s name-:
#include<iostream>
using namespace std;
class Test
{
int x;
public:
void setX (int x)
{ // The 'this' pointer is used to retrieve the object's x
// hidden by the local variable 'x'
this->x = x;
}
void print() { cout << "x = " << x << endl; }
};
int main()
{
Test obj;
int x = 20;
obj.setX(x);
obj.print();
return 0;
}
- To return reference to the calling object-: Usecase-: Chain Function Calls
#include<iostream>
using namespace std;
class Test
{
int x;
int y;
public:
Test(int x = 0, int y = 0) { this->x = x; this->y = y; }
Test &setX(int a) { x = a; return *this; }
Test &setY(int b) { y = b; return *this; }
void print() { cout << "x = " << x << " y = " << y << endl; }
};
int main()
{
Test obj1(5, 5);
obj1.setX(10).setY(20);
obj1.print();
return 0;
}
- Smart Pointers-: auto_ptr, shared_ptr, unique_ptr and weak_ptr pointers. (For more information jump to Dynamic Memory Allocation section)
- Wild Pointers-: A pointer which has not been initialized to anything (not even NULL) is known as wild pointer. The pointer may be initialized to a non-NULL garbage value that may not be a valid address. Every uninitialized pointer is a wild pointer unless it has been initialized.
- Near, Far & Huge Pointers-: Near pointer is used to store 16 bit addresses means within current segment on a 16 bit machine. The limitation is that we can only access 64kb of data at a time. A far pointer is typically 32 bit that can access memory outside current segment. To use this, compiler allocates a segment register to store segment address, then another register to store offset within current segment. Like far pointer, huge pointer is also typically 32 bit and can access outside segment. In case of far pointers, a segment is fixed. In far pointer, the segment part cannot be modified, but in Huge it can be.
- Opaque Pointers-: Opaque pointer is a pointer which points to a data structure whose contents are not exposed at the time of its definition. Following pointer is opaque. One can’t know the data contained in STest structure by looking at the definition. struct STest* pSTest;
- Pointer to a function -: int * foo(int); operator precedence also plays role here ..so in this case, operator () will take priority over the asterisk operator . And the above declaration will mean – a function foo with one argument of int type and return value of int * i.e. integer pointer. Solution-: int (* foo)(int); //there's no space between * and foo. Added space to avoid text formatting of a markdown file.
- Note-: The Arrow(->) operator exists to access the members of the structure or the unions using pointers.
🟥🟩🟦
- When a class is defined, no memory is allocated but when it is instantiated (i.e. an object is created) memory is allocated. Object take up space in memory and have an associated address.
- The standard does not permit objects (or classes) of size 0, this is because that would make it possible for two distinct objects to have the same memory location. This is the reason behind the concept that even an empty class must have a size at least 1. It is known that size of an empty class is not zero. Generally, it is 1 byte. For dynamic allocation also, the new keyword returns different address for the same reason.
- By default the access modifier for the members will be Private. Only the member functions or the friend functions are allowed to access the private data members of a class. Protected access modifier is similar to private access modifier in the sense that it can’t be accessed outside of it’s class unless with the help of friend class, the difference is that the class members declared as Protected can be accessed by any subclass(derived class) of that class as well. This access through inheritance can alter the access modifier of the elements of base class in derived class depending on the modes of Inheritance. (For more info jump to Inheritance section). A friend class can access private and protected members of other class in which it is declared as friend. It is sometimes useful to allow a particular class to access private members of other class. For example a LinkedList class may be allowed to access private members of Node.
class Node {
private:
int key;
Node* next;
// Other members of Node Class
// Now class LinkedList can
// access private members of Node
friend class LinkedList;
};
- Note-: Friendship is not mutual & Friendship is not inherited. . If a base class has a friend function, then the function doesn’t become a friend of the derived class(es).
- Note-: Like member functions and member function arguments, the objects of a class can also be declared as const. an object declared as const cannot be modified and hence, can invoke only const member functions as these functions ensure not to modify the object.
- Constructors-:
- They can be defined in private section of class and thus can only be used by a friend class.
- Types of Contructors-:
- Default Constructor -: Consider a class derived from another class with the default constructor, or a class containing another class object with default constructor. The compiler needs to insert code to call the default constructors of base class.
- Parameterized Constructor
- Copy Constructor -: is a member function which initializes an object using another object of the same class.
- OBJECT COPYING-: It is the process of creating a copy of an existing object. Copying is done mostly so the copy can be modified or moved, or the current value preserved. If either of these is unneeded, a reference to the original data is sufficient and more efficient, as no copying occurs.
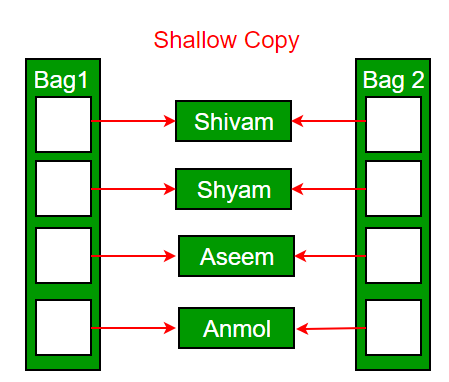
Note-: If we write ABC ob2=ob1; copy constructor is called for the object copying. But if we write ABC ob2; ob2=ob1; then the default overloded = operator is caled for the object copying. Types-: 1. Shallow copy-: In that case a new object B is created, and the values of the data members of A are copied to the data members of B. And if the classes have a pointer variable then the memory is shared between the pointer variable of A as well as of B.
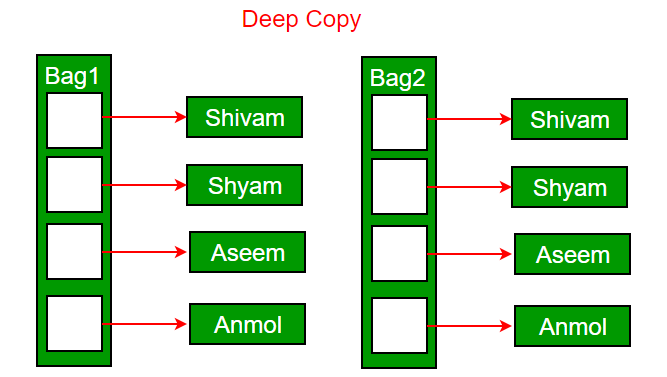
- Deep copy-: In that case a new object B is created, and the values of the data members of A are copied to the data members of B. And if the classes have a pointer variable then a seperate memory block is created for the pointer variable of B. Thus the memory is not shared between the pointer variable of A and B. >>>
- Lazy copy-: A lazy copy is an implementation of a deep copy. When initially copying an object, a (fast) shallow copy is used. A counter is also used to track how many objects share the data. When the program wants to modify an object, it can determine if the data is shared (by examining the counter) and can do a deep copy if needed. Lazy copy looks to the outside just as a deep copy, but takes advantage of the speed of a shallow copy whenever possible.
**Compiler's Optimizations**
1. Copy Elision-: or Copy omission is a compiler optimization technique that avoids unnecessary copying of objects.
e.g. For B ob = "copy me"; // B is a class
According to theory, when the object “ob” is being constructed, one argument constructor is used to convert “copy me” to a temporary object & that
temporary object is copied to the object “ob”. But now the call to the copy constructor is elided.
2. Return Value Optimization-: is a compiler optimization that involves eliminating the temporary object created to hold a function's return value.
#include<iostream>
using namespace std;
class Point
{
private:
int x, y;
public:
Point(int x1, int y1) { x = x1; y = y1; }
Point(const Point& p1) {x = p1.x; y = p1.y; }
int getX() { return x; }
int getY() { return y; }
};
int main()
{
Point p1(10, 15); // Normal constructor is called here
Point p2=p1; // Copy constructor is called here
cout << "p1.x = " << p1.getX() << ", p1.y = " << p1.getY();
cout << "\np2.x = " << p2.getX() << ", p2.y = " << p2.getY();
return 0;
}
A copy constructor is called when an object is passed by value. Copy constructor itself is a function. So if we pass an argument by value in a copy
constructor, a call to copy constructor would be made to call copy constructor which becomes a non-terminating chain of calls. Therefore compiler doesn’t
allow parameters to be passed by value.
Why const?
#include<iostream>
using namespace std;
class Test
{
/* Class data members */
public:
Test(Test &t) { /* Copy data members from t*/}
Test() { /* Initialize data members */ }
};
Test fun()
{
cout << "fun() Called\n";
Test t;
return t;
}
int main()
{
Test t1;
Test t2 = fun();
return 0;
}
>>>Compile time error. Reason-: The function fun() returns by value. So the compiler creates a temporary object which is copied to t2 using copy constructor
in the original program (The temporary object is passed as an argument to copy constructor). The reason for compiler error is, compiler created temporary
objects cannot be bound to non-const references because it doesn’t make sense to modify compiler created temporary objects as they can die any moment.
Solution-: 1. Use const. 2. Test t2; t2 = fun();
In C++, a Copy Constructor may be called in following cases:
1. When an object of the class is returned by value.
2. When an object of the class is passed (to a function) by value as an argument.
3. When an object is constructed based on another object of the same class.
4. When the compiler generates a temporary object.
It is, however, not guaranteed that a copy constructor will be called in all these cases, because the C++ Standard allows the compiler to optimize the copy
away in certain cases, one example is the return value optimization (sometimes referred to as RVO)
Note-: In C++ computer programming, copy elision refers to a compiler optimization technique that eliminates unnecessary copying of objects. The C++
language standard generally allows implementations to perform any optimization, provided the resulting program's observable behavior is the same as if, i.e.
pretending, the program were executed exactly as mandated by the standard.
In the context of the C++ programming language, return value optimization (RVO) is a compiler optimization that involves eliminating the temporary object
created to hold a function's return value.The standard also describes a few situations where copying can be eliminated even if this would alter the
program's behavior, the most common being the return value optimization.
If we don’t define our own copy constructor, the C++ compiler creates a default copy constructor for each class which does a member-wise copy between
objects. The compiler created copy constructor works fine in general. We need to define our own copy constructor only if an object has pointers or any
runtime allocation of the resource like file handle, a network connection..etc. Default copy constructor does only shallow copy. Deep copy is possible only
with user defined copy constructor.
Copy constructor is called when a new object is created from an existing object, as a copy of the existing object (see this G-Fact). And assignment operator
is called when an already initialized object is assigned a new value from another existing object.
- Conversion Constructor
- Explicit Constructor
- Dynamic Constructor
- Dummy Constructor
- Move Constructor
- Destructor-:
- When something is created using dynamic memory allocation, it is programmer’s responsibility to delete it. So compiler doesn’t bother.
- When a class has private destructor, only dynamic objects of that class can be created and use a function as friend of the class to call delete().
- It cannot be declared static or const.
- An object of a class with a Destructor cannot become a member of the union.
- The programmer cannot access the address of destructor.
- There can only one destructor in a class
- It is always a good idea to make destructors virtual in base class when we have a virtual function.
- Types of Destructors-:
- Virtual Destructor-: Discussed in the Virtual Function & Runtime Polymorphism (Function Overriding) section.
- Pure Destructor
- Whenever we define one or more non-default constructors( with parameters ) for a class, a default constructor( without parameters ) should also be explicitly defined as the compiler will not provide a default constructor in this case.
🟥🟩🟦
- Static Local Variables-: It can be useful to have a local variable whose lifetime continues across calls to the function. We obtain such objects by defining a local variable as static. Each local static object is initialized before the first time execution passes through the object’s definition. Local statics are not destroyed when a function ends; they are destroyed when the program terminates. (Note-: Even the global objects are destroyed when the main fucntion ends.)
int count_calls()
{
static int ctr = 0; // value will persist across calls
return ++ctr;
}
int main()
{
for (int i = 0; i != 10; ++i)
cout << count_calls() << endl;
return 0;
}
- This program will print the numbers from 1 through 10 inclusive.
- Note-: If a local static has no explicit initializer, it is value initialized, meaning that local statics of built-in type are initialized to zero by the default constructor.
- Static class members-: Classes sometimes need members that are associated with the class, rather than with individual objects of the class type. For example, a bank account class might need a data member to represent the current prime interest rate. In this case, we’d want to associate the rate with the class, not with each individual object. From an efficiency standpoint, there’d be no reason for each object to store the rate. Much more importantly, if the rate changes, we’d want each object to use the new value.
- The static members of a class exist outside any object. Objects do not contain data associated with static data members. Similarly, static member functions are not bound to any object; they do not have a this pointer. As a result, static member functions may not be declared as const. Note-: 1. We can access a static member using the scope operator or using an object, reference or pointer of class type. 2. Member functions can use static members directly, without the scope operator.
class Account {
public:
void calculate() { amount += amount * interestRate; }
static double rate() { return interestRate; }
static void rate(double);
private:
std::string owner;
double amount;
static double interestRate;
static double initRate();
};
void Account::rate(double newRate)
{
interestRate = newRate;
}
int main(){
double r;
r = Account::rate();
Account ac1;
Account * ac2 = &ac1;
r = ac1.rate();
r = ac2->rate();
- Note-:
- A static member function can be called even if no objects of the class exist and the static functions are accessed using only the class name and the scope resolution operator ::
- Static member function: it can only access static member data, or other static member functions while non-static member functions can access all data members of the class: static and non-static.
- A static can be declared inside a class and can only be defined outside the class.
- Static variables are allocated memory in data segment, not stack segment.
- Static Objects-: Objects also when declared as static have a scope till the lifetime of program.
#include<iostream>
using namespace std;
class GfG
{
int i = 0;
public:
GfG()
{
i = 0;
cout << "Inside Constructor\n";
}
~GfG()
{
cout << "Inside Destructor\n";
}
};
int main()
{
int x = 0;
if (x==0)
{
static GfG obj;
}
cout << "End of main\n";
}
- Output-: Inside Constructor End of main Inside Destructor
🟥🟩🟦
Types-:
- Abstraction using Classes: We can implement Abstraction in C++ using classes. The class helps us to group data members and member functions using available access specifiers. A Class can decide which data member will be visible to the outside world and which is not.
- Abstraction in Header files: One more type of abstraction in C++ can be header files. For example, consider the pow() method present in math.h header file. Whenever we need to calculate the power of a number, we simply call the function pow() present in the math.h header file and pass the numbers as arguments without knowing the underlying algorithm according to which the function is actually calculating the power of numbers.
🟥🟩🟦
- Modes Of Inheritance-:
- Public mode: If we derive a sub class from a public base class. Then the public member of the base class will become public in the derived class and protected members of the base class will become protected in derived class.
- Protected mode: If we derive a sub class from a Protected base class. Then both public member and protected members of the base class will become protected in derived class.
- Private mode: If we derive a sub class from a Private base class. Then both public member and protected members of the base class will become Private in derived class.
- Note : The private members in the base class cannot be directly accessed in the derived class, while protected members can be directly accessed.
- Constructor Calls in Inheritance-: Base class constructors are always called in the derived class constructors. Whenever you create derived class object, first the base class default constructor is executed and then the derived class's constructor finishes execution.
- Points to Remember-:
- Whether derived class's default constructor is called or parameterised is called, base class's default constructor is always called inside them.
- To call base class's parameterised constructor inside derived class's parameterised constructo, we must mention it explicitly while declaring derived class's parameterized constructor.
#include<iostream>
using namespace std;
class Base
{ int x;
public:
Base(int i)
{ x = i;
cout << "Base Parameterized Constructor\n";
}
};
class Derived : public Base
{ int y;
public:
// parameterized constructor
Derived(int j):Base(j)
{ y = j;
cout << "Derived Parameterized Constructor\n";
}
};
int main()
{ Derived d(10) ;
}
- Why is Base class Constructor called inside Derived class? -> Constructors have a special job of initializing the object properly. A Derived class constructor has access only to its own class members, but a Derived class object also have inherited property of Base class, and only base class constructor can properly initialize base class members. Hence all the constructors are called, else object wouldn't be constructed properly.
- Note-:
- Constructors and Destructors are never inherited and hence never overrided.(We will study the concept of function overriding in the next tutorial)
- Assignment operator = is never inherited. It can be overloaded but can't be inherited by sub class.
- Inheritance and Static Functions in C++ -:
- They are inherited into the derived class.
- If you redefine a static member function in derived class, all the other overloaded functions in base class are hidden.
- Static Member functions can never be virtual. We will study about Virtual in coming topics.
- Types of Inheritance-:
- Single Inheritance: In single inheritance, a class is allowed to inherit from only one class. i.e. one sub class is inherited by one base class only.
- Multiple Inheritance (V): Multiple Inheritance is a feature of C++ where a class can inherit from more than one classes. i.e one sub class is inherited from more than one base classes.
- Single Inheritance: In single inheritance, a class is allowed to inherit from only one class. i.e. one sub class is inherited by one base class only.
- Note-: The constructors of inherited classes are called in the same order in which they are inherited and the destructors are called in reverse order of constructors.
- Multilevel Inheritance-: In this type of inheritance, a derived class is created from another derived class.
- Hierarchical Inheritance (A)-: In this type of inheritance, more than one sub class is inherited from a single base class. i.e. more than one derived class is created from a single base class.
- Hybrid (Virtual) Inheritance: Hybrid Inheritance is implemented by combining more than one type of inheritance. For example: Combining Hierarchical inheritance and Multiple Inheritance.
- Multilevel Inheritance-: In this type of inheritance, a derived class is created from another derived class.
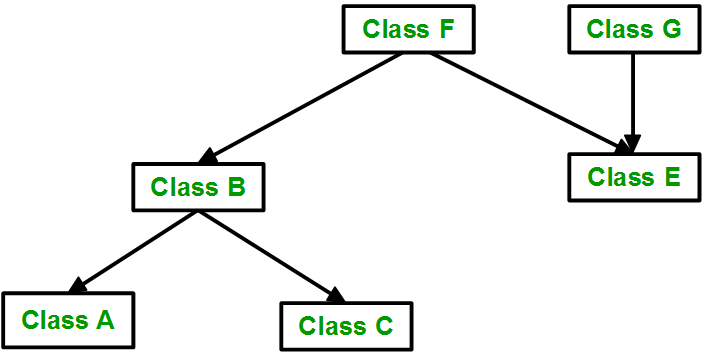
🟥🟩🟦
- Upcasting -: is a process of creating a pointer or a reference of the derived class object as a base class pointer. You do not need to upcast manually. You just need to assign derived class pointer (or reference) to base class pointer.
- When you use upcasting, the object is not changing. Nevertheless, when you upcast an object, you will be able to access only member functions and data members that are defined in the base class.
- One of the biggest advantages of upcasting is the capability of writing generic functions for all the classes that are derived from the same base class.
#include <iostream>
using namespace std;
class Person
{
//content of Person
};
class Employee:public Person
{
public:
Employee(string fName, string lName, double sal)
{
FirstName = fName;
LastName = lName;
salary = sal;
}
string FirstName;
string LastName;
double salary;
void show()
{
cout << "First Name: " << FirstName << " Last Name: " << LastName << " Salary: " << salary<< endl;
}
void addBonus(double bonus)
{
salary += bonus;
}
};
class Manager :public Employee
{
public:
Manager(string fName, string lName, double sal, double comm) :Employee(fName, lName, sal)
{
Commision = comm;
}
double Commision;
double getComm()
{
return Commision;
}
};
class Clerk :public Employee
{
public:
Clerk(string fName, string lName, double sal, Manager* man) :Employee(fName, lName, sal)
{
manager = man;
}
Manager* manager;
Manager* getManager()
{
return manager;
}
};
void congratulate(Employee* emp) //generic function
{
cout << "Happy Birthday!!!" << endl;
emp->addBonus(200);
emp->show();
};
int main()
{
//pointer to base class object
Employee* emp;
//object of derived class
Manager m1("Steve", "Kent", 3000, 0.2);
Clerk c1("Kevin","Jones", 1000, &m1);
//implicit upcasting
emp = &m1;
//It's ok
cout<<emp->FirstName<<endl;
cout<<emp->salary<<endl;
//Fails because upcasting is used
//cout<<emp->getComm();
congratulate(&c1);
congratulate(&m1);
cout<<"Manager of "<<c1.FirstName<<" is "<<c1.getManager()->FirstName;
}
>>Steve
3000
Happy Birthday!!!
First Name: Kevin Last Name: Jones Salary: 1200
Happy Birthday!!!
First Name: Steve Last Name: Kent Salary: 3200
Manager of Kevin is Steve
- Memory Layout-:
-> It represents the fact that when you use a base class pointer to point up an object of the derived class, you can access only elements that are defined in the base class (green area). Elements of the derived class (yellow area) are not accessible when you use a base class pointer.
- Downcasting is an opposite process for upcasting. It converts base class pointer to derived class pointer. Downcasting must be done manually. It means that you have to specify explicit typecast.
- Downcasting is not as safe as upcasting. You know that a derived class object can be always treated as a base class object. However, the opposite is not right.
- You have to use an explicit cast for downcasting:

-
//pointer to base class object Employee* emp; //object of derived class Manager m1("Steve", "Kent", 3000, 0.2); //implicit upcasting emp = &m1; //explicit downcasting from Employee to Manager Manager* m2 = (Manager*)(emp); >>>This code compiles and runs without any problem because emp points to an object of Manager class.
-
But, Employee e1("Peter", "Green", 1400); //try to cast an employee to Manager Manager* m3 = (Manager*)(&e1); cout << m3->getComm() << endl; >>>e1 object is not an object of the Manager class. It does not contain any information about the commission. That’s why such an operation can produce unexpected results. - Memory layout-:
- Dynamic_Cast-: is an operator that converts safely one type to another type. In the case, the conversation is possible and safe, it returns the address of the object that is converted. Otherwise, it returns nullptr.
- If you want to use a dynamic cast for downcasting, the base class should be polymorphic – it must have at least one virtual function. Modify base class Person by adding a virtual function:
- virtual void foo() {}
-
Employee e1("Peter", "Green", 1400); Manager* m3 = dynamic_cast<Manager*>(&e1); if (m3) cout << m3->getComm() << endl; else cout << "Can't cast from Employee to Manager" << endl; - In this case, the dynamic cast returns nullptr. Therefore, you will see a warning message.
🟥🟩🟦
- Types of polymorphism-:
- Binding-: refers to the process of converting identifiers (such as variable and function names) into addresses. Binding is done for each variable and functions. For functions, it means that matching the call with the right function definition by the compiler. It takes place either at compile time or at runtime.
- Early Binding (compile-time time polymorphism or static binding or static dispatch or comipile-time dispatch) As the name indicates, compiler (or linker) directly associate an address to the function call. It replaces the call with a machine language instruction that tells the mainframe to leap to the address of the function. By default early binding happens in C++.
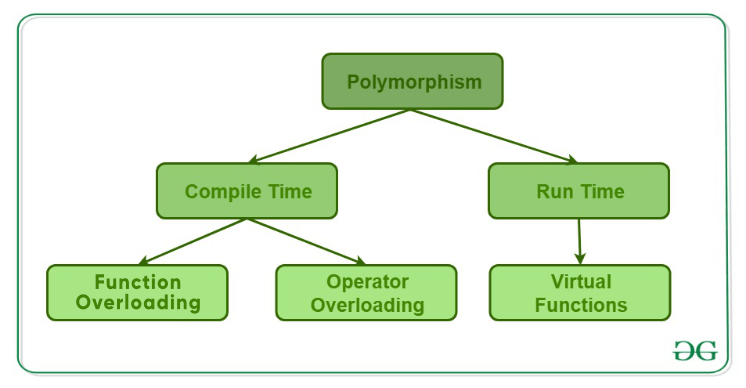
- Operator Overloading-:
- Most overloaded operators may be defined as ordinary non-member functions or as class member functions. Box operator+(const Box&); In case we define above function as non-member function of a class then we would have to pass two arguments for each operand as Box operator+(const Box&, const Box&);
- Operators which cannot be overloaded-:
- ?: (conditional)
- . (member selection)
- .* (member selection with pointer-to-member)
- :: (scope resolution)
- sizeof (object size information)
- typeid (object type information)
- static_cast (casting operator)
- const_cast (casting operator)
- reinterpret_cast (casting operator)
- dynamic_cast (casting operator)
- For operator overloading to work, at least one of the operands must be a user defined class object.
- Overloaded operators cannot have default arguments except the function call operator () which can have default arguments.
- Compiler automatically creates a default assignment operator with every class.
- Assignment (=), subscript ([]), function call (“()”), and member selection (->) operators must be defined as member functions, all other operators can be either member functions or a non member functions.
- Some operators like assignment (=), address (&) and comma (,) are by default overloaded.
- Consider the statement “ob1 + ob2” (let ob1 and ob2 be objects of two different classes). To make this statement compile, we must overload ‘+’ in class of ‘ob1’ or make ‘+’ a global function. Which can be quite inconvenient in some cases (e.g. <<,>>).
- In case of the Output Operator << -: Ordinarily, the first parameter of an output operator is a reference to a nonconst ostream object. The ostream is nonconst because writing to the stream changes its state. The parameter is a reference because we cannot copy an ostream object. The second parameter ordinarily should be a reference to const of the class type we want to print. The parameter is a reference to avoid copying the argument. It can be const because (ordinarily) printing an object does not change that object.
void operator<<(ostream &os, const book &item)
{
os << item.isbn() << " " << item.units_sold << " "
<< item.revenue << " " << item.avg_price();
}
Note-: Differentiating Prefix and Postfix Operators-: Normal overloading cannot distinguish between these operators. The prefix and postfix versions use the same symbol, meaning that the overloaded versions of these operators have the same name. They also have the same number and type of operands. To solve this problem, the postfix versions take an extra (unused) parameter of type int. When we use a postfix operator, the compiler supplies 0 as the argument for this parameter.
-
- Function Overloading-:
- Parameter declarations that differ only in a pointer * versus an array [] are equivalent. That is, the array declaration is adjusted to become a pointer declaration. Only the second and subsequent array dimensions are significant in parameter types. For example, following two function declarations are equivalent
- int fun(int * ptr);
- int fun(int ptr[]); // redeclaration of fun(int * ptr)
🟥🟩🟦
- Late Binding (Run time polymorphism or dynamic binding or dynamic dispatch or run-time dispatch)-: In this, the compiler adds code that identifies the kind of object at runtime then matches the call with the right function definition.
- A Base Class pointer can point to a derived class object. Why is the vice-versa not true? -> A derived class contains the properties of it's super class but the super class doesn't contain the properties of the derived class. A derived object is a base class object (as it's a sub class), so it can be pointed to by a base class pointer. However, a base class object is not a derived class object so it can't be assigned to a derived class pointer.
- A base class pointer can point to a derived class object, but we can only access base class member or virtual functions using the base class pointer because object slicing happens when a derived class object is assigned to a base class object. Additional attributes of a derived class object are sliced off to form the base class object.
- Example of the above point-: A class base contains the following function definition-: virtual void fun_4() { cout << "base-4\n"; } and the derived class conatins the following: void fun_4(int x) { cout << "derived-4\n"; }. Then doing this-: base* p; derived obj1; p = &obj1; p->fun_4(5); is illegal.
- Object Slicing-: happens when a derived class object is assigned to a base class object, additional attributes of a derived class object are sliced off to form the base class object.
#include <iostream>
using namespace std;
class Base
{
protected:
int i;
public:
Base(int a) { i = a; }
virtual void display()
{ cout << "I am Base class object, i = " << i << endl; }
};
class Derived : public Base
{
int j;
public:
Derived(int a, int b) : Base(a) { j = b; }
virtual void display()
{ cout << "I am Derived class object, i = "
<< i << ", j = " << j << endl; }
};
void somefunc (Base obj)
{
obj.display();
}
int main()
{
Base b(33);
Derived d(45, 54);
somefunc(b);
somefunc(d); // Object Slicing, the member j of d is sliced off
return 0;
}
- I am Base class object, i = 33 I am Base class object, i = 45
- Solution 1-: Object slicing doesn’t occur when pointers or references to objects are passed as function arguments since a pointer or reference of any type takes same amount of memory and prevents copying. -> void somefunc (Base &obj)
- Solution 2-: Object slicing can be prevented by making the base class function pure virtual there by disallowing object creation. It is not possible to create the object of a class which contains a pure virtual method.
- A virtual function is a member function that you expect to be redefined in derived classes. When you refer to a derived class object using a pointer or a reference to the base class, you can call a virtual function for that object and execute the derived class's version of the function.
#include <iostream>
using namespace std;
class Account {
public:
Account( double d ) { _balance = d; }
virtual double GetBalance() { return _balance; }
virtual void PrintBalance() { cerr << "Error. Balance not available for base type." << endl; }
private:
double _balance;
};
class CheckingAccount : public Account {
public:
CheckingAccount(double d) : Account(d) {}
void PrintBalance() { cout << "Checking account balance: " << GetBalance() << endl; }
};
class SavingsAccount : public Account {
public:
SavingsAccount(double d) : Account(d) {}
void PrintBalance() { cout << "Savings account balance: " << GetBalance(); }
};
int main() {
CheckingAccount checking( 100.00 );
SavingsAccount savings( 1000.00 );
Account *pAccount = &checking;
pAccount->PrintBalance();
pAccount = &savings;
pAccount->PrintBalance();
}
- In the preceding code, the calls to PrintBalance are identical, except for the object pAccount points to. Because PrintBalance is virtual, the version of the function defined for each object is called. The PrintBalance function in the derived classes CheckingAccount and SavingsAccount "override" the function in the base class Account.In the preceding code, the calls to PrintBalance are identical, except for the object pAccount points to. Because PrintBalance is virtual, the version of the function defined for each object is called. The PrintBalance function in the derived classes CheckingAccount and SavingsAccount "override" the function in the base class Account.
- A function that is virtual in a base class is implicitly virtual in its derived classes-: When a derived class overrides a virtual function, it may, but is not required to, repeat the virtual keyword. Once a function is declared as virtual, it remains virtual in all the derived classes.
- If a class is declared that does not provide an overriding implementation of the PrintBalance function, the default implementation from the base class Account is used.
- Rules-: 1. A call to a virtual function is resolved according to the underlying type of object for which it is called. 2. A call to a nonvirtual function is resolved according to the type of the pointer or reference. 3. Because virtual functions are called only for objects of class types, you cannot declare global or static functions as virtual. 4. A class may have virtual destructor but it cannot have a virtual constructor. (More details later)
- Use-: Virtual functions allow us to call methods of any of the derived classes without even knowing kind of derived class object.
- Usecase-: To raise the salary of each employee in the organisation-:
class Employee {
public:
virtual void raiseSalary()
{
/* common raise salary code */
}
virtual void promote() { /* common promote code */ }
};
class Manager : public Employee {
virtual void raiseSalary()
{
/* Manager specific raise salary code, may contain
increment of manager specific incentives*/
}
virtual void promote()
{
/* Manager specific promote */
}
};
// Similarly, there may be other types of employees
// We need a very simple function
// to increment the salary of all employees
// Note that emp[] is an array of pointers
// and actual pointed objects can
// be any type of employees.
// This function should ideally
// be in a class like Organization,
// we have made it global to keep things simple
void globalRaiseSalary(Employee* emp[], int n)
{
for (int i = 0; i < n; i++
// Polymorphic Call: Calls raiseSalary()
// according to the actual object, not
// according to the type of pointer
emp[i]->raiseSalary();
}
- Working of the above code and the concept of VTABLE and VPTR-:
- vtable: A table of function pointers, maintained per class and created at compile time.
- vptr: A pointer to vtable, maintained per object instance and is inherited by derived classes.
- If a class contains a virtual function then compiler itself does two things: 1. If object of that class is created then a virtual pointer (VPTR) is inserted as a data member of the class to point to virtual table (VTABLE) of that class. For each new object created, a new virtual pointer is inserted as a data member of that class. 2. Irrespective of object is created or not, a static array of function pointer called VTABLE where each cell contains the address of each virtual function contained in that class.
- For the code above this is what happens under the hood-:
- Compiler adds additional code at two places to maintain and use vptr-:

- Code in every constructor. This code sets the vptr of the object being created. This code sets vptr to point to the vtable of the class.
- Wherever a polymorphic call is made, the compiler inserts code to first look for vptr using base class pointer or reference (In the above example, since pointed or referred object is of derived type, vptr of derived class is accessed). Once vptr is fetched, vtable of derived class can be accessed. Using vtable, address of derived class function raisesalary() is accessed and called.
- Example-:
#include <iostream>
using namespace std;
class A
{
public:
virtual void fun();
};
class B
{
public:
void fun();
};
int main()
{
int a = sizeof(A), b = sizeof(B);
if (a == b) cout << "a == b";
else if (a > b) cout << "a > b";
else cout << "a < b";
return 0;
}
- Output -> a > b
- Explanation-: Class A has a VPTR which is not there in class B. In a typical implementation of virtual functions, compiler places a VPTR with every object. Compiler secretly adds some code in every constructor to this.
- Note-: By default all the functions defined inside the class are implicitly or automatically considered as inline except virtual functions. Whenever virtual function is called using base class reference or pointer it cannot be inlined (because call is resolved at runtime), but whenever called using the object (without reference or pointer) of that class, can be inlined because compiler knows the exact class of the object at compile time.
- Deleting a derived class object using a pointer of base class type that has a non-virtual destructor results in undefined behavior. To correct this situation, the base class should be defined with a virtual destructor. Making base class destructor virtual guarantees that the object of derived class is destructed properly, i.e., both base class and derived class destructors are called. Any time you have a virtual function in a class, you should immediately add a virtual destructor (even if it does nothing).
- Pure Virtual Functions & Abstract Classes-: Sometimes implementation of all function cannot be provided in a base class because we don’t know the implementation. Such a class is called abstract class. For example, let Shape be a base class. We cannot provide implementation of function draw() in Shape, but we know every derived class must have implementation of draw(). A pure virtual function (or abstract function) in C++ is a virtual function for which we don’t have implementation, we only declare it. A pure virtual function is declared by assigning 0 in declaration. ---
-
// An abstract class class Test { // Data members of class public: // Pure Virtual Function virtual void show() = 0; };
- Note-:
- A class is abstract if it has at least one pure virtual function.
- If we do not override the pure virtual function in derived class, then derived class also becomes abstract class.
- We cannot create objects of abstract classes. Reasoon-: Because it's abstract and an object is concrete. An abstract class is sort of like a template, or an empty/partially empty structure, you have to extend it and build on it before you can use it. Take for example an "Animal" abstract class. There's no such thing as a "pure" animal - there are specific types of animals. So you can instantiate Dog and Cat and Turtle, but you shouldn't be able to instantiate plain Animal - that's just a basic template. And there's certain functionality that all animals share, such as "makeSound()", but that can't be defined on the base Animal level. So if you could create an Animal object and you would call makeSound(), how would the object know which sound to make?
- An abstract class can have constructors. Reason-: An abstract class can have member variables and potentially non-virtual member functions, so that every derived class from the former implements specific features. Then, the responsibility for the initialization of these members variables may belong to the abstract class (at least always for private members, because the derived class wouldn't be able to initialize them, yet could use some inherited member functions that may use/rely on these members). Thus, it makes it perfectly reasonable for abstract classes to implement constructors.
- We can have pointers and references of abstract class type (But they should not be pointing at the astract class's object but to any of the derived class's object.
- Multiple Inheritace and Hybrid Inheritance -> Virtual Inheritance (The Diamond Problem) -> Virtual Base Class -: The diamond problem occurs when two superclasses of a class have a common base class. For example, in the following diagram, the TA class gets two copies of all attributes of Person class, this causes ambiguities.

#include<iostream>
using namespace std;
class Person {
// Data members of person
public:
Person(int x) { cout << "Person::Person(int ) called" << endl; }
};
class Faculty : public Person {
// data members of Faculty
public:
Faculty(int x):Person(x) {
cout<<"Faculty::Faculty(int ) called"<< endl;
}
};
class Student : public Person {
// data members of Student
public:
Student(int x):Person(x) {
cout<<"Student::Student(int ) called"<< endl;
}
};
class TA : public Faculty, public Student {
public:
TA(int x):Student(x), Faculty(x) {
cout<<"TA::TA(int ) called"<< endl;
}
};
int main() {
TA ta1(30);
}
Person::Person(int ) called
Faculty::Faculty(int ) called
Person::Person(int ) called
Student::Student(int ) called
TA::TA(int ) called
- In the above program, constructor of ‘Person’ is called two times. Destructor of ‘Person’ will also be called two times when object ‘ta1’ is destructed. So object ‘ta1’ has two copies of all members of ‘Person’, this causes ambiguities. The solution to this problem is ‘virtual’ keyword. We make the classes ‘Faculty’ and ‘Student’ as virtual base classes to avoid two copies of ‘Person’ in ‘TA’ class. (Concept of Virtual explained later in the Virtual Function & Runtime Polymorphism (Function Overriding) section)
- Virtual Base Class-: Virtual base classes are used in virtual inheritance in a way of preventing multiple “instances” of a given class appearing in an inheritance hierarchy when using multiple inheritances.
#include<iostream>
using namespace std;
class Person {
public:
Person(int x) { cout << "Person::Person(int ) called" << endl; }
Person() { cout << "Person::Person() called" << endl; }
};
class Faculty : virtual public Person {
public:
Faculty(int x):Person(x) {
cout<<"Faculty::Faculty(int ) called"<< endl;
}
};
class Student : virtual public Person {
public:
Student(int x):Person(x) {
cout<<"Student::Student(int ) called"<< endl;
}
};
class TA : public Faculty, public Student {
public:
TA(int x):Student(x), Faculty(x) {
cout<<"TA::TA(int ) called"<< endl;
}
};
int main() {
TA ta1(30);
}
Person::Person() called
Faculty::Faculty(int ) called
Student::Student(int ) called
TA::TA(int ) called
- Note-: One important thing to note in the above output is, the default constructor of ‘Person’ is called. When we use ‘virtual’ keyword, the default constructor of grandparent class is called by default even if the parent classes explicitly call parameterized constructor.
- Calling the parameterized constructor of the grandparent class
#include<iostream>
using namespace std;
class Person {
public:
Person(int x) { cout << "Person::Person(int ) called" << endl; }
Person() { cout << "Person::Person() called" << endl; }
};
class Faculty : virtual public Person {
public:
Faculty() {
cout<<"Faculty::Faculty(int ) called"<< endl;
}
};
class Student : virtual public Person {
public:
Student() {
cout<<"Student::Student(int ) called"<< endl;
}
};
class TA : public Faculty, public Student {
public:
TA(int x):Student(), Faculty(), Person(x) {
cout<<"TA::TA(int ) called"<< endl;
}
};
int main() {
TA ta1(30);
}
Person::Person(int ) called
Faculty::Faculty(int ) called
Student::Student(int ) called
TA::TA(int ) called
- Note-: In general, it is not allowed to call the grandparent’s constructor directly, it has to be called through parent class. It is allowed only when ‘virtual’ keyword is used.
- e.g. 2 -> If B and C are sub classes of A and are superclasses of D then to access the data members of the grandparent class we can use ::
obj.ClassB::a = 10;
obj.ClassC::a = 100;
obj.b = 20;
obj.c = 30;
obj.d = 40;
🟥🟩🟦
- Terminate function-: Library function that is called if an exception is not caught. Terminate aborts the program. If no appropriate catch is found, execution is transferred to a library function named terminate. The behavior of that function is system dependent but is guaranteed to stop further execution of the program. Exceptions that occur in programs that do not define any try blocks are handled in the same manner: After all, if there are no try blocks, there can be no handlers. If a program has no try blocks and an exception occurs, then terminate is called and the program is exited.
- The fact that control passes from throw clause to a catch block, has two important implications: • Functions along the call chain may be prematurely exited. • When a handler is entered, objects created along the call chain will have been destroyed.
- what() method-: Each of the library exception classes defines a member function named what. These functions take no arguments and return a C style character string (i.e., a const char*).
- Stack Unwinding-: The process of removing function entries from function call stack at run time is called Stack Unwinding. Workflow-: If the throw appears inside a try block, the catch clauses associated with that try are examined. If a matching catch is found, the exception is handled by that catch. Otherwise, if the try was itself nested inside another try, the search continues through the catch clauses of the enclosing trys. If no matching catch is found, the current function is exited, and the search continues in the calling function. If the call to the function that threw is in a try block, then the catch clauses associated with that try are examined. If a matching catch is found, the exception is handled. Otherwise, if that try was nested, the catch clauses of the enclosing trys are searched. If no catch is found, the calling function is also exited. The search continues in the function that called the just exited one, and so on.
- Note-: When a block is exited during stack unwinding, the compiler guarantees that objects created in that block are properly destroyed. If a local object is of class type, the destructor for that object is called automatically.
#include <iostream>
using namespace std;
void f1() throw (int) {
cout<<"\n f1() Start ";
throw 100;
cout<<"\n f1() End ";
}
void f2() throw (int) {
cout<<"\n f2() Start ";
f1();
cout<<"\n f2() End ";
}
void f3() {
cout<<"\n f3() Start ";
try {
f2();
}
catch(int i) {
cout<<"\n Caught Exception: "<<i;
}
cout<<"\n f3() End";
}
int main() {
f3();
getchar();
return 0;
}
- Output-:
f3() Start
f2() Start
f1() Start
Caught Exception: 100
f3() End
- Object destruction-: When an exception is thrown, destructors of the objects (whose scope ends with the try block) is automatically called before the catch block gets exectuted. Destructors are only called for the completely constructed objects. When constructor of an object throws an exception, destructor for that object is not called. Reason-: In C++ the lifetime of an object is said to begin when the constructor runs to completion. And it ends right when the destructor is called. If the constructor throws, then the destructor is not called.
#include <iostream>
using namespace std;
class Test1 {
public:
Test1() { cout << "Constructing an Object of Test1" << endl; }
~Test1() { cout << "Destructing an Object of Test1" << endl; }
};
class Test2 {
public:
Test2() { cout << "Constructing an Object of Test2" << endl;
throw 20; }
~Test2() { cout << "Destructing an Object of Test2" << endl; }
};
int main() {
try {
Test1 t1; // Constructed and destructed
Test2 t2; // Partially constructed
Test1 t3; // t3 is not constructed as this statement never gets executed
} catch(int i) {
cout << "Caught " << i << endl;
}
}
- Output-:
Constructing an Object of Test1
Constructing an Object of Test2
Destructing an Object of Test1
Caught 20
- User Defined Exception-:
#include <iostream>
using namespace std;
class demo1 {
demo1(){
cout<<"demo1 constructor called"<<endl;
};
class demo2 {
demo2(){
cout<<"demo2 constructor called"<<endl;
};
int main()
{
for (int i = 1; i <= 2; i++) {
try {
if (i == 1)
throw demo1();
else if (i == 2)
throw demo2();
}
catch (demo1 d1) {
cout << "Caught exception of demo1 class \n";
}
catch (demo2 d2) {
cout << "Caught exception of demo2 class \n";
}
}
}
- Output-:
demo1 constructor called
Caught exception of demo1 class
demo2 constructor called
Caught exception of demo2 class
- Rethrowing an exception-: Sometimes a single catch cannot completely handle an exception. After some corrective actions, a catch may decide that the exception must be handled by a function further up the call chain. A catch passes its exception out to another catch by rethrowing the exception. A rethrow is a throw that is not followed by an expression: throw; An empty throw can appear only in a catch or in a function called (directly or indirectly) from a catch. If an empty throw is encountered when a handler is not active, terminate is called. A rethrow does not specify an expression; the (current) exception object is passed up the chain. In general, a catch might change the contents of its parameter. If, after changing its parameter, the catch rethrows the exception, then those changes will be propagated only if the catch’s exception declaration is a reference:
-
catch (my_error &eObj) { // specifier is a reference type eObj.status = errCodes::severeErr; // modifies the exception object throw; // the status member of the exception object is severeErr } catch (other_error eObj) { // specifier is a nonreference type eObj.status = errCodes::badErr; // modifies the local copy only throw; // the status member of the exception object is unchanged }
- Finally block implementation in c++ -: C++ doesn't support the finally block (which is used in programming languages like Java) instead it uses a concept, RAII (Resource Acquisition Is Initialization). The idea is that an object's destructor is responsible for freeing resources. When the object has automatic storage duration, the object's destructor will be called when the block in which it was created exits -- even when that block is exited in the presence of an exception. Actual code and implementation is out of the scope of this repo and most of the c++ books.
- The method of Generic Programming or Generics is implemented to increase the efficiency of the code. Generic Programming enables the programmer to write a general algorithm which will work with all data types. It eliminates the need to create different algorithms if the data type is an integer, string or a character. Generics can be implemented in C++ using Templates.
- Templates-: Template is a simple and yet very powerful tool in C++. The simple idea is to pass data type as a parameter so that we don’t need to write the same code for different data types. They are of two types-: Function Templates (or Generic Function) and Class Templates (or Generic Class). Templates are expanded at compiler time. This is like macros. The difference is, compiler does type checking before template expansion.
- Generic Function-:
#include <iostream>
using namespace std;
template <typename T>
T myMax(T x, T y)
{
return (x > y) ? x : y;
}
int main()
{
cout << myMax<int>(3, 7) << endl;
cout << myMax<double>(3.0, 7.0) << endl;
cout << myMax<char>('g', 'e') << endl;
return 0;
}
- Output-: 7 7 g
- Generic Classes-: Like function templates, class templates are useful when a class defines something that is independent of data type. Can be useful for classes like LinkedList, binary tree, Stack, Queue, Array, etc.
#include <iostream>
using namespace std;
template <typename T>
class Array {
private:
T *ptr;
int size;
public:
Array(T arr[], int s);
void print();
};
template <typename T>
Array<T>::Array(T arr[], int s) {
ptr = new T[s];
size = s;
for(int i = 0; i < size; i++)
ptr[i] = arr[i];
}
template <typename T>
void Array<T>::print() {
for (int i = 0; i < size; i++)
cout<<" "<<*(ptr + i);
cout<<endl;
}
int main() {
int arr[5] = {1, 2, 3, 4, 5};
Array<int> a(arr, 5);
a.print();
return 0;
}
- Output-: 1 2 3 4 5
- Multi-type Generics and default arguments-:
#include<iostream>
using namespace std;
template<class T, class U=char>
class A {
T x;
U y;
public:
A() { cout<<"Constructor Called"<<endl; }
};
int main() {
A<char> a;
A<int, double> b;
return 0;
}
- Output-: Constructor Called Constructor Called
- Note-: Each instantiation of function template has its own copy of local static variables. e.g. Two copies of static variable i exist will exist for the templates of the same function, void fun(int ) and void fun(double ).
- Template Specialization-: Consider a big project that needs a function sort() for arrays of many different data types. Let Quick Sort be used for all datatypes except char. In case of char, total possible values are 256 and counting sort may be a better option. Is it possible to use different code only when sort() is called for char data type? It is possible in C++ to get a special behavior for a particular data type. This is called template specialization.
- Working-: If a specialized version is present in your code, compiler first checks with the specialized version and then the main template. Compiler first checks with the most specialized version by matching the passed parameter with the data type(s) specified in a specialized version.
- Function Template Specialization-:
#include <iostream>
using namespace std;
template <class T>
void fun(T a)
{
cout << "The main template fun(): "
<< a << endl;
}
template<>
void fun(int a)
{
cout << "Specialized Template for int type: "
<< a << endl;
}
int main()
{
fun<char>('a');
fun<int>(10);
fun<float>(10.14);
}
- Output-: The main template fun(): a Specialized Template for int type: 10 The main template fun(): 10.14
- Class Template Specialization-:
#include <iostream>
using namespace std;
template <class T>
class Test
{
public:
Test()
{
// Initialization of data members
cout << "General template object \n";
}
};
template <>
class Test <int>
{
public:
Test()
{
// Initialization of data members
cout << "Specialized template object\n";
}
};
int main()
{
Test<int> a;
Test<char> b;
Test<float> c;
return 0;
}
- Output-: Specialized template object General template object General template object 🟥🟩🟦
- The mechanism by which storage/memory/cells can be allocated to variables during the runtime is called Dynamic Memory Allocation. Dynamic memory allocation can be done on both stack and heap. An example of dynamic allocation to be done on the stack is recursion where the functions are put into call stack in order of their occurrence and popped off one by one on reaching the base case. For dynamically allocated memory like “int *p = new int[10]”, it is programmers responsibility to deallocate memory when no longer needed. If programmer doesn’t deallocate memory, it causes memory leak.
- new operator-: The new operator denotes a request for memory allocation on the Free Store. If sufficient memory is available, new operator initializes the memory and returns the address of the newly allocated and initialized memory to the pointer variable.
- e.g. Allocating memory using new operator-:
int *p = NULL;
p = new int;
OR
int *p = new int;
- e.g. Initializing memory using new operator-: int *p = new int(25);
- e.g. Allocating block of memory using new operator-: int *a = new int[10];
- delete operator-: Since it is programmer’s responsibility to deallocate dynamically allocated memory, programmers are provided delete operator. e.g. delete p;
- To free the dynamically allocated array pointed by pointer-variable, use following form of delete: delete[] a;
- Exception handling of new operator-: When new operator request for the memory then if there is a free memory is available then it returns valid address or else it throws bad_alloc exception.
#include <iostream>
using namespace std;
int main(int argc, char** argv) {
int *piValue = NULL;
try
{
piValue = new int[9999999999999]; // allocate huge amount of memory
}
catch(...)
{
cout<<"Free memory is not available"<<endl;
return -1;
}
delete []piValue;
return 0;
}
- Output-: Free memory is not available
- To avoid the exception throw we can use “nothrow” with the new operator. When we are used “nothrow” with new operator then it returns a valid address if it is available either return 0 (NULL).
- Note-: We need to include file for the use of “nothrow” with the new operator.
#include <iostream>
#include <new>
using namespace std;
int main() {
int *piValue = NULL;
piValue = new(nothrow) int[999999999999999]; // We are using nothrow here.
if(piValue == NULL) // or if(!piValue)
{
cout<<"Free memory is not available"<<endl;
}
else
{
cout<<"Free memory available"<<endl;
delete []piValue;
}
return 0;
}
- Dynamic Objects-: C++ programming language allows both auto(or stack allocated) and dynamically allocated objects. In java & C#, all objects must be dynamically allocated using new. C++ supports stack allocated objects for the reason of runtime efficiency. Stack based objects are implicitly managed by C++ compiler. They are destroyed when they go out of scope and dynamically allocated objects must be manually released, using delete operator otherwise memory leak occurs. C++ doesn’t support automatic garbage collection approach used by languages such as Java & C#.
- e.g. A * a = new A() //dynamic object of class A
- e.g. A * a = new A[10] // array of dynamic objects
- Specific examples of memory leak in dynamic memory allocation-: Dynamically allocated memory stays allocated until it is explicitly deallocated or until the program ends (and the operating system cleans it up, assuming your operating system does that). However, the pointers used to hold dynamically allocated memory addresses follow the normal scoping rules for local variables. e.g. 1-:
void doSomething()
{
int *ptr{ new int{} };
}
- This function allocates an integer dynamically, but never frees it using delete. Because pointers variables are just normal variables, when the function ends, ptr will go out of scope. And because ptr is the only variable holding the address of the dynamically allocated integer, when ptr is destroyed there are no more references to the dynamically allocated memory. This means the program has now “lost” the address of the dynamically allocated memory. As a result, this dynamically allocated integer can not be deleted.
- e.g. 2-:
int value = 5;
int *ptr{ new int{} }; // allocate memory
ptr = &value; // old address lost, memory leak results
- Fix-:
int value{ 5 };
int *ptr{ new int{} }; // allocate memory
delete ptr; // return memory back to operating system
ptr = &value; // reassign pointer to address of value
- e.g. 3-:
int *ptr{ new int{} };
ptr = new int{}; // old address lost, memory leak results
- Because of the laziness or carelessness of the programmer this type of problem may arise thus c++ introduced smart pointers.
- Smart Pointers-: Using Smart Pointers, we can make pointers to work in a way that we don’t need to explicitly call delete. A smart pointer is a wrapper class over a pointer with an operator like * and -> overloaded. Types-:
- Note-: Smart pointers are defined in the memory header file in the std namespace so don't forget to include the header file.
- unique_ptr-: The idea behind a unique pointer is that if a pointer is pointing at an memory that holds an object then we can't copy or assign that pointer variable to another because if we do so then two different pointers would be pointing at the same memory and if any one of them is deleted that the memory to which it was pointing is freed and thus the other pointer is now pointing at a memory which has been freed which is illogical and irrelevant. The object to which a unique_ptr points is destroyed when the unique_ptr is destroyed.
unique_ptr<double> p1; // unique_ptr that can point at a double
unique_ptr<int> p2(new int(42)); // p2 points to int with value 42
unique_ptr<string> p1(new string("Stegosaurus"));
unique_ptr<string> p2(p1); // error: no copy for unique_ptr
unique_ptr<string> p3;
p3 = p2; // error: no assign for unique_ptr
- Although we can’t copy or assign a unique_ptr, we can transfer ownership from one (nonconst) unique_ptr to another by calling release or reset:
// transfers ownership from p1 (which points to the string Stegosaurus) to p2
unique_ptr<string> p2(p1.release()); // release makes p1 null
unique_ptr<string> p3(new string("Trex"));
// transfers ownership from p3 to p2
p2.reset(p3.release()); // reset deletes the memory to which p2 had pointed
- Note-: For exception safety, the preferred way to create an unique pointer is -: unique_ptr p2= make_unique(42);
- shared_ptr-: If you are using shared_ptr then more than one pointer can point to this one object at a time and it’ll maintain a Reference Counter (no. of pointers pointing at a memory address) using use_count() method. Shared pointers allocate another block of memory called the control block to store the reference count.
#include <iostream>
using namespace std;
#include <memory>
class Rectangle {
int length;
int breadth;
public:
Rectangle(int l, int b)
{
length = l;
breadth = b;
}
~Rectangle() { cout<<"Dest called"<<endl;}
int area()
{
return length * breadth;
}
};
int main()
{
shared_ptr<Rectangle> P1(new Rectangle(10, 5));
cout << P1->area() << endl;
shared_ptr<Rectangle> P2;
P2 = P1;
cout << P2->area() << endl;
cout << P1->area() << endl;
cout << P1.use_count() << endl;
return 0;
}
- Output-: 50 50 50 2 Dest called
- Note-: An object referenced by the pointer will not be destroyed until reference count is equal to zero i.e. until all copies of shared_ptr have been deleted.
- Note-: If we create a shared pointer using the new keyword the statement results in the allocation of two blocks of memory. One for the object and one for the control block.Therefore the preferred way to create a shared pointer is -: shared_ptr p2= make_shared(42);
- weak_ptr-: A weak_ptr is a smart pointer that does not control the lifetime of the object to which it points. Instead, a weak_ptr points to an object that is managed by a shared_ptr. Binding a weak_ptr to a shared_ptr does not change the reference count of that shared_ptr. Once the last shared_ptr pointing to the object goes away, the object itself will be deleted. That object will be deleted even if there are weak_ptrs pointing to it—hence the name weak_ptr, which captures the idea that a weak_ptr shares its object “weakly”. The existence or destruction of weak_ptr has no effect on the shared_ptr or its other copies.
share_ptr<int> p = make_shared<int>(42);
weak_ptr<int> wp(p); // wp weakly shares with p; use count in p is unchanged
// Here both wp and p point to the same object. Because the sharing is weak, creating wp doesn’t change the reference count of p; it
// is possible that the object to which wp points might be deleted.
- Note-: Because the object might no longer exist, we cannot use a weak_ptr to access its object directly. To access that object, we must call lock. The lock function checks whether the object to which the weak_ptr points still exists. If so, lock returns a shared_ptr to the shared object or else returns null.
if (shared_ptr<int> np = wp.lock()) { // true if np is not null
// inside the if, np shares its object with p
}
- Usecase of weak_ptr-:
- Cyclic Dependency (Problems with shared_ptr): Let’s consider a scenario where we have two classes A and B, both have pointers to other classes. So, it’s always like A is pointing to B and B is pointing to A. Hence, use_count will never reach zero and they never get deleted.
. This is the reason we use weak pointers(weak_ptr) as they are not reference counted. So, the class in which weak_ptr is declared doesn’t have a stronghold of it i.e. the ownership isn’t shared, but they can have access to these objects.
- Dangling Pointers-: A pointer pointing to a memory location that has been deleted (or freed) is called dangling pointer.

#include <iostream>
int main()
{
char **strPtr;
char *str = "Hello!";
strPtr = &str;
delete str;
//strPtr now becomes a dangling pointer
cout<<*strPtr;
strPtr=NULL; // isn't a dangling pointer anymore
}
🟥🟩🟦
- Typedef-: C++ allows you to define explicitly new data type names by using the keyword typedef. Using typedef does not actually create a new data class, rather it defines a name for an existing type.
#include <iostream>
using namespace std;
typedef unsigned char BYTE;
int main()
{
BYTE b1, b2;
b1 = 'c';
cout << " " << b1;
return 0;
}
- Type Inferences-: Type Inference refers to automatic deduction of the data type of an expression in a programming language. All the types are deduced in compiler phase only, the time for compilation increases slightly but it does not affect the run time of the program. Implementation-:
- auto keyword-: The auto keyword specifies that the type of the variable that is being declared will be automatically deducted from its initializer. In case of functions, if their return type is auto then that will be evaluated by return type expression at runtime.The variable declared with auto keyword should be initialized at the time of its declaration only or else there will be a compile-time error
#include <bits/stdc++.h>
using namespace std;
int main()
{
auto x = 4;
auto y = 3.37;
auto ptr = &x;
cout << typeid(x).name() << endl
<< typeid(y).name() << endl
<< typeid(ptr).name() << endl;
return 0;
}
- Output-: i d pi
- Note : auto becomes int type if even an integer reference is assigned to it. To make it reference type, we use auto &.
- decltype -: It inspects the declared type of an entity or the type of an expression. Auto lets you declare a variable with particular type whereas decltype lets you extract the type from the variable so decltype is sort of an operator that evaluates the type of passed expression.
#include <bits/stdc++.h>
using namespace std;
int fun1() { return 10; }
char fun2() { return 'g'; }
int main()
{
decltype(fun1()) x;
decltype(fun2()) y;
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
return 0;
}
- Output-: i c
#include <bits/stdc++.h>
using namespace std;
int main()
{
int x = 5
decltype(x) j = x + 5;
cout << typeid(j).name();
return 0;
}
- Output-: i
- The "return 0;" statement is optional for the main method. The compiler automatically adds it for us during the compilation of the code.
- Exiting from the code before encountering the return statement of any method (including main)-: For this c++ provides us with the exit method and _Exit method.
- Note-: exit() function performs some cleaning before termination of the program like connection termination, buffer flushes etc. The _Exit() function in C/C++ gives normal termination of a program without performing any cleanup tasks.
- Difference-:
#include<bits/stdc++.h>
using namespace std;
void fun(void)
{
cout << "Exiting";
}
int main()
{
atexit(fun);
exit(10);
}
- Output-: Exiting
#include<bits/stdc++.h>
using namespace std;
void fun(void)
{
cout << "Exiting";
}
int main()
{
atexit(fun);
_Exit(10);
}
- No output.
- Command Line Arguments-: Command-line arguments are given after the name of the program in command-line shell of Operating Systems. To pass command line arguments, we typically define main() with two arguments : first argument is the number of command line arguments and second is list of command-line arguments. argc (ARGument Count) is int and stores number of command-line arguments passed by the user including the name of the program. So if we pass a value to a program, value of argc would be 2 (one for argument and one for program name). The value of argc should be non negative. argv(ARGument Vector) is array of character pointers listing all the arguments. If argc is greater than zero,the array elements from argv[0] to argv[argc-1] will contain pointers to strings. Argv[0] is the name of the program , After that till argv[argc-1] every element is command -line arguments.
- Run this code on your linux machine-:
#include <iostream>
using namespace std;
int main(int argc, char** argv)
{
cout << "You have entered " << argc
<< " arguments:" << "\n";
for (int i = 0; i < argc; ++i)
cout << argv[i] << "\n";
return 0;
}
- Variadic function template-: Variadic templates are template that take a variable number of arguments. Variadic function templates are functions which can take multiple number of arguments. Note-: Defining a base function for the variadic function template is compulsory and it is always called at the end.
#include <iostream>
using namespace std;
// To handle base case of below recursive Variadic function Template
void print()
{
cout << "I am empty function and "
"I am called at last.\n" ;
}
template <typename T, typename... Types>
void print(T var1, Types... var2)
{
cout << var1 << endl ;
print(var2...) ;
}
int main()
{
print(1, 2, 3.14, "Pass me any "
"number of arguments",
"I will print\n");
return 0;
}
- Output-: 1 2 3.14 Pass me any number of arguments I will print I am empty function and I am called at last.
- Local classes-: A class declared inside a function becomes local to that function and is called Local Class
- Note-: All the methods of Local classes must be defined inside the class only.
#include<iostream>
using namespace std;
void fun()
{
class Test // local to fun
{
public:
void method() {
cout << "Local Class method() called";
} //method() cannot be defined outside the class even if it is within the function.
};
Test t;
t.method();
}
int main()
{
fun();
return 0;
}
- Output-: Local Class method() called
- Note-: A Local class cannot contain static data members. It may contain static functions though.
- Note-: Member methods of local class can only access static variables of the enclosing function.
- Note-: Local classes can access global types, variables and functions. Also, local classes can access other local classes of same function.
- Nested class-: A nested class is a class which is declared in another enclosing class. A nested class is a member and as such has the same access rights as any other member. The members of an enclosing class have no special access to members of a nested class; the usual access rules shall be obeyed.
int x,y; // globals
class enclose { // enclosing class
int x; // note: private members
static int s;
public:
class inner { // nested class
void f(int i) {
x = i; // Error: can't write to non-static enclose::x without instance
s = i; // OK: can assign to the static enclose::s
::x = i; // OK: can assign to global x
y = i; // OK: can assign to global y
}
void g(enclose* p, int i) {
p->x = i; // OK: assign to enclose::x
}
};
};
- Range based for loop-: It executes a for loop over a range.
for (auto n : {0, 1, 2, 3, 4, 5})
cout << n << ' ';
int a[] = {0, 1, 2, 3, 4, 5};
for (int n : a)
std::cout << n << ' ';
string str = "Geeks";
for (char c : str)
std::cout << c << ' ';
🟥🟩🟦
- Stanley B. Lippman's C++ Primer
- Stack Overflow
- GeeksForGeeks
- Wikipedia