How It Works
Background on how the goldparser-rs crate works. Much of this information is available in the GOLD Parser System documentation, but as it's not been updated and I'm unsure of its continuing availability, I've included relevant portions here.
One of the primary goals of the [GOLD Parsing System is to support any number of programming languages. To accomplish this, the logic used to construct parse tables is logically removed from the algorithms that do the actual parsing.
When a grammar is analyzed by the GOLD Builder, parse tables are constructed for the Deterministic Finite Automata (DFA) and Look Ahead, Left to Right (LALR) algorithms. Both the DFA and LALR algorithms are simple automatas, and can be easily implemented in different programming languages with a minimum of code. The Engine has already been implemented in Visual Basic, C++, C#, ANSI C, Javascript, x86 ASM, Java and Delphi.
Once the parse tables are constructed, they can be saved to a compiled Enhanced Grammar Table file (.egt). This file is platform and programming language independent. As a result, different implementations of the Engine can load the file and use its information.
🌐 Source: http://goldparser.org/doc/cgt/index.htm
While the text of a program is easy to understand by humans, the computer must convert it into a form which it can understand before any emulation or compilation can begin.
This process is know generally as "parsing" and consists of two distinct parts.
The first part is the "Tokenizer" - also called a "lexer" or "scanner". The Tokenizer takes the source text and breaks it into the reserved words, constants, identifiers, and symbols that are defined in the language. These "Tokens" are subsequently passed to the actual 'parser' which analyzes the series of Tokens and then determines when one of the language's syntax rules is complete.
As these completed rules are "reduced" by the parser, a tree following the language's grammar and representing the program is created. In this form, the program is ready to be interpreted or compiled by the application.
Modern bottom-up parsers use a Deterministic Finite Automaton (DFA) to implement the Tokenizer and a LALR(1) state machine to parse the created Tokens. Practically all common parser generators, such as the UNIX standard YACC, use these algorithms.
The actual LALR(1) and DFA algorithms are easy to implement since they rely on tables to determine actions and state transition. Consequently, it is the computing of these tables that is both time-consuming and complex.
The GOLD Parser Builder performs this task. Information is read from an source grammar and the the appropriate tables are computed . These tables are then saved to a file which can be, subsequently, loaded by the actual parser engine and used.
The primary goal a parser is to organize a sequence of Tokens based on the rules of a formal language. As the parser accepts a sequence of Tokens, it determines, based on this information, when the grammar's respective rules are complete and verifies the syntactic correctness of the Token sequence. The end result of the process is a "derivation" which represents the Token sequence organized following the rules of the grammar.
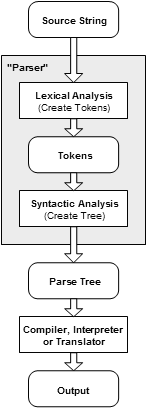
Typically, Backus-Naur Form is used to define the context free grammar used by the language. The entire language, as a whole, is represented through a single nonterminal called the "start symbol". Often the parse information is stored into a tree, called a derivation tree, where the start symbol is the root node.
There are two distinct approaches currently used to implement parsers. Recursive Descent Parsers and LL parsers are examples of top-down parsers and LR parsers are examples of bottom-up parsers. Most parser generators, such as YACC, use one of the LR algorithm variants.
One of the major components of GOLD (and many other parsing systems) is the Tokenizer. The goal of the Tokenizer (also called a scanner) is to recognize different Tokens and pass this information to the parsing algorithm.
Essentially, regular expressions can be used to define a regular language. Regular languages, in turn, exhibit very simple patterns. A deterministic finite automaton, or DFA for short, is a method if recognizing this pattern algorithmically.
As the name implies, deterministic finite automata are deterministic. This means that from any given state there is only one path for any given input. In other words, there is no ambiguity in state transition. It is also complete which means there is one path from any given input. It is finite; meaning there is a fixed and known number of states and transitions between states. Finally, it is an automaton. The transition from state to state is completely determined by the input. The algorithm merely follows the correct branches based on the information provided.
A DFA is commonly represented with a graph. The term "graph" is used quite loosely by other scientific fields. Often, it is refers to a plotted mathematical function or graphical representation of data. In computer science terms, however, a "graph" is simply a collection of nodes connected by edges.
Most parser engines, including the GOLD Parsing System, use a DFA to implement the Tokenizer. This part of the engine scans the input and determines when and if a series of characters can be recognized as a Token.
The figure to the right is a simple Deterministic Finite Automata that recognizes common identifiers and numbers.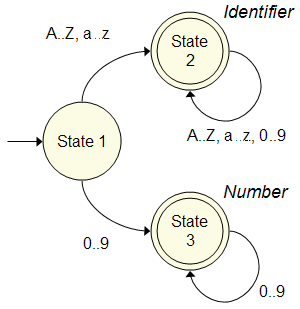
By design, the Tokenizer attempts to match the longest series of characters possible before accepting a Token. For example: if the Tokenizer is reading the characters "count" from the source, it can match the first character "c" as an identifier. It would not be prudent for the Tokenizer to report five separate identifiers: "c", "o", "u", "n" and "t".
Each time a Token is identified, it is passed to the LALR parse engine and the Tokenizer restarts at the initial state.
For more information, please refer to the following:
Loudan, Kenneth C. (1997). Compiler Construction, PWS Publishing Company, 20 Park Plaza,
Boston, MA 02116-4324
Appel, Andrew W. (1998). Modern Compiler Implementation in C. Cambridge University Press, 40
West 20th Street, New York City, New York 10011-4211
Fischer, Charles N. & LeBlanc Jr., Richard J. (1988). Crafting a Compiler, The
Benjamin/Cummings Publishing Company Inc., 2727 Sand Hill Road, Menlo Park, California 94025
LR Parsing, or Left-to-right Right-derivation parsing, uses tables to determine when a rule is complete and when additional Tokens must be read from the source string. LR parsers identify substrings which can be reduced to nonterminals. Unlike recursive descent parsers, LR parsers do very little "thinking" at runtime. All decisions are based on the content of the parse tables.
LR parser generators construct these tables by analyzing the grammar and determining all the possible "states" the system can have when parsing. Each state represents a point in the parse process where a number of Tokens have been read from the source string and rules are in different states of completion. Each production in a state of completion is called a "configuration" and each state corresponds to a configuration set. Each configuration contains a "cursor" which represents the point where the production is complete.

LALR Parsing, or "Lookahead LR parsing", is a variant of LR Parsing which most parser generators, such as YACC, implement. LR Parsing combines related "configuration sets" thereby limiting the size of the parse tables. As a result, the algorithm is slightly less powerful than LR Parsing but much more practical.
Grammars that can be parsed by the LR algorithm, might not be able to be parsed by the LALR algorithm. However, this is very rarely the case and real-world examples are few. The number of states eliminated by choosing LALR over LR is sometimes huge. The C programming language, for instance, has over 10,000 LR states. LALR drops this number to around 350.
Typically, the LR / LALR parsing algorithms, like deterministic finite automata, are commonly represented by using a graph - albeit a more complex variant. For each Token received from the scanner, the LR algorithm can take four different actions: Shift, Reduce, Accept and Goto.
For each state, the LR algorithm checks the next Token on the input queue against all Tokens that expected at that stage of the parse. If the Token is expected, it is "shifted". This action represents moving the cursor past the current Token. The Token is removed form the input queue and pushed onto the parse stack.
A reduce is performed when a rule is complete and ready to be replaced by the single nonterminal it represents. Essentially, the Tokens that are part of the rule's handle - the right-hand side of the definition - are popped from the parse stack and replaced by the rule's nonterminal plus additional information including the current state in the LR state machine.
When a rule is reduced, the algorithm jumps to (gotos) the appropriate state representing the reduced nonterminal. This simulates the shifting of a nonterminal in the LR state machine.
Finally, when the start symbol itself is reduced, the input is both complete and correct. At this point, parsing terminates.
For more information, please refer to the following:
Loudan, Kenneth C. (1997). Compiler Construction, PWS Publishing Company,
20 Park Plaza, Boston, MA 02116-4324
Appel, Andrew W. (1998). Modern Compiler Implementation in C. Cambridge
University Press, 40 West 20th Street, New York City, New York 10011-4211
Fischer, Charles N. & LeBlanc Jr., Richard J. (1988). Crafting a Compiler,
The Benjamin/Cummings Publishing Company Inc., 2727 Sand Hill Road,
Menlo Park, California 94025
Using a BNF-style notation, describe your language and use the GOLD Parser GUI or GOLD Parser Builder CLI to generate a compiled Enhanced Grammar Table. If you prefer, you can use Yacc to define your language and then use yacctogold.
The goldparser-rs repository contains a binary (
egtutil) that uses the Rust parser engine to perform various actions on your EGT, including printing out each section, and an interactive REPL-style shell into the grammar tables.