alternative filename storage for very long filenames #7
Comments
|
-1 this significantly increases the cost of Readme.md: Fast on classical HDDs EncFS is typically much faster than ecryptfs for stat()-heavy workloads when the backing device is a classical hard disk. This is because ecryptfs has to to read each file header to determine the file size - EncFS does not. This is one additional seek for each stat. See PERFORMANCE.md for detailed benchmarks on HDD, SSD and ramdisk. |
|
It isn't necessary to store all filenames this way, just the ones that would otherwise be too long. Ideally you would only pay a performance penalty when using long filenames, otherwise you wouldn't see a difference. |
|
Got it. Because encrypted files may be moved across different host filesystems, "too long filesystem" must be defined independent of host filesystem. Practically, most filesystems support 255 bytes (https://en.wikipedia.org/wiki/Comparison_of_file_systems). So this issue is more specifically, "alternative filename storage for filenames over 190 characters". |
|
Not only too long filenames might raise problems but also too long pathnames. I would really like to see an option for encfs to set maximum length of filenames and pathnames separately. |
|
FWIW, there are two reasons I'm looking for an alternative to ecryptfs, and the top one is file name length; ecryptfs' limit (135 characters IIRC) is just not workable for 2015. (The second reason is performance on regular hard disks, which is why I ended up looking at encfs.) |
|
For people that are following this issue, I am interested to know if it is because your file names are long or because there is a lot of folder nesting? If it is the latter then storing file name in the file wont help here. Here is one solution: Store naming information in a "directory file" in each directory. Example cipher text: This solution creates a locking problem with index.idx. |
|
It's because the filenames are long, for me at least. Some programs generate filenames automatically based on some data or another, hashes in particular, and they assume filesystems have a reasonable limit, something like 256. One such program had a bug reported on that topic and closed it with a “wontfix” since, well, if it's just one or two filesystems that have such a small limit, better that people just don't use those, eh? :-) |
|
Most people have probably never had to worry about short names (8+3 anyone?), and hash-based names have become common with programs like Git, as it provides a convenient way to do content-based addressing. So I think that long names are here to stay. One problem is that encryption expands the names, so those long names become even longer. It seems feasible to hide long names from the underlying FS without big changes to the encfs, and without impacting performance of anyone who isn't using long names. For example, handle filenames as normal unless it has a certain prefix, in which case you have to read the name from elsewhere (like the file header). Older versions of encfs would be able to read everything but the long files, as it wouldn't be able to decode those names. As @fulldecent points out, there isn't any one consistent limit to target, so this would probably be a FS config option. Producing shorter paths would be a more major overhaul, not something I'd imagine being backward compatible with existing filesystems. So I'm not inclined to worry about path limits. |
|
I'd be fine with this solution. What do you wean with the config option? Minimum length to encode, or maximum to allow? I think the latter isn't necessary at all — it would be kind of ironic if after this change encfs becomes one of the few fs to allow arbitrarily long filenames and then you need to rename your files when you want to move them out 😉 And minimum length to encode can be easily autodetected on mount, based on the host filesystem limit + encoding overhead. |
|
Config would be for the maximum encoded name length. Since Encfs volumes can be moved between systems, an Encfs folder could always contain longer names than the underlying storage system supports, so it's no different than what a user would already face if they tried to move files from one filesystem to one with more restrictive limits. |
|
My problem is Wouldn't it be possible to have an option that would store metadata in a separate file or something? I don't care about the performance. I just want everything to work smoothly. |
|
+1
|
|
Just because i am curious: what kind of filenames are you working with that
are so long?
(The paste link you sent does not work)
|
As I mentioned above I use ext4
Sorry. I created a new one: |
|
What I mean is that I don't understand why you have file names that are so
long. Must be over 160 character unencrypted.
|
I'm not sure what if there is file name(s) more than 160 chr. as unencrypted form but what I'm sure of is I don't face any problem during copy files using cp or rsync in unencrypted mode |
|
Transmission creates “resume” files which are IIRC the torrent's filename plus its hash. I of course know nothing whatsoever about illegal torrents, but legitimate ones often have very long names, with project name, release number, source, and sometimes a small CRC; when Transmission adds the hash, those often go over 160. I've “solved” that by keeping those out of encfs ;-) since there's not much point in encrypting them. But if someone wants to encrypt their entire home (as I used to before switching to encfs), that would be a problem. |
|
Just being creative here. What if this capability was delivered by a separate Fuse module called, say, For #7, we would support the feature For the future, other options may include: making filenames lowercase (case insensitive), restricting file length (splitting), restricting dots at the beginning of the name, saving OS X metadata into flat files, restricting directory depth, unicode filenames, getting around other restrictions in https://en.wikipedia.org/wiki/Comparison_of_file_systems This glue would be useful to anyone needing to store files into a more restrictive file system (backups/rsyncs, other use cases above). And this would be reusable for people needing the above but not needing encryption. |
|
Guys I'm really confused. What the verdict of this discussion? Do I've to stop using EncFS because of this bug? Thanks for your contributions and I wish to get a solution because until now EncFS is the only choice for me under Linux. |
|
@hpctech I am sorry, but I think it is unlikely that this will be fixed.
|
|
@fulldecent I think a “fold” filesystem is a good idea in its own merit. It's not a fix for this issue, though, which is an EncFS bug. To put it simply: if you're a filesystem, and you're going to generate filenames based on the original name plus something, it's your job to make sure it still works. As a tangential point, since there's a direct correlation between encoded name length and original name length, I tend to feel the level of protection/encryption is less than ideal. For particularly large data sets, this could be exploited to correlate them, especially when combining with file sizes, and then you have a huge body of plain text to help break the encryption. |
|
@rfjakob It seems I've to move to cryptomator although it's not efficient as EncFS |
|
@vgough From the Debian packaging front, there is https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=536752 about this issue... is there any workaround that gets your blessing? |
|
The fact that issue is still open indicates indecision and prevents everyone from working towards a consensus solution (or multiple competing solutions). @rfjakob [Above](Update missing ALT tags) you mention:
If this is true, I would respectfully request this issue to be closed as WONTFIX. Further, your endorsement of a |
|
William, i will gladly support a pull request if you implement this, and so I will read through the proposals tomorrow and think about what i find the |
|
@fulldecent Just to revisit the current design, it is like this: [ plain text filename ] --- encryption ---> [ encrypted blob ] --- base64 ---> [ encrypted filename ]
[ plain text filename ] --- encryption ---> [ encrypted blob ] --- sha256 --- hexdump ---> [ filename hash ] The file would be called I think this is the way to go. Build it into encfs instead of creating an external filesystem. This would be difficult to test and use and hence error prone and fragile. The construction using the sha256 hash makes sure file lookup is efficient even for long file names. There should be no performance impact for directories not containing long file names. Each long file name in a folder will hit readdir performance with the penalty of reading the |
|
@rfjakob I have been looking at this and am almost ready to get started. Previously I was thinking to do a separate filesystem which solves this and other problems. For that, the approach:
is great. The only problem is that [ plain text filename ] --- encryption ---> [ encrypted blob ] --- base64 --- substr ---> [ encrypted prefix ] The file would be called Does this make sense? |
|
Hi there, I have implemented the scheme I proposed in gocryptfs by now (latest master), if you want to take a look. fopen should be O(1) because you just open the file by hash instead of by name. Readdir becomes O(n + 2*m), with n the number of short files and m the number of long files in the directory. |
|
Got it, thank you. My main use case is |
|
Oh, reverse mode! No, this would be O(n), as you said. But it looks like the substring approach would be just the same. You still have to read the whole directory to find the right file. But for reverse mode you can cache the plaintext <-> hash relation. Having maybe 1000 cached entries will probably eliminate most directory reads. |
|
I had similar idea for another overlay filesystem that just resolves for "too long filenames" otherwise proxy 1:1 with underlaying filesystem. While searching for such "fuse overlaying filesystem too long filename" , I've found that I am not the only one with idea: #7 (comment) . Has anyone actually came across some fuse overlay filesystem providing such functionality? Cross referencing: I've asked also here: http://unix.stackexchange.com/q/283149/9689 |
|
@gwpl In summary from this discussion above: a filename-translating filesystem works and the way to set it up is pretty clear; but the reversing process can be slow because of how filesystems work. |
|
@fulldecent , I assume you've meant that it's builtin for EncFS, do you ? Btw. If EncFS has support for encoding long filenames, one might want to update: |
|
No, it's not built into EncFS (yet). Regarding ecryptfs, I am sceptical that you can mount ecryptfs on to of a FUSE file system. It doesn't even work properly on NFS ( https://bugs.launchpad.net/ecryptfs/+bug/277578 ). |
|
@rfjakob so is it gocryptfs? |
|
Hi, another question about filenames: is there a way to make |
|
The index-file (a special file that is stored in every directory) could be made in something like sqlite, thus improving the performance somewhat (although probably would not allow for multithreading). Besides some extra complexity and an extra dependency, is this solution generally better than "longfn.[ filename hash ].fullname"- approach? I think many people who will use this (for backups especially) will not care much about filename-seeking performance. (Or will not come to use cases where this performance will matter. The number of files will be so small relative to the current performance of common storage solutions.) Also many times the path length is indeed the problem (on windows a lot), but in practice it only becomes the problem because encfs bloats the filenames. Considering this, if we implement "longfn" solution, the actual signature itself should be shorter than "longfn" - preferably only one character, like "l.". (That is still enough as a signature because it will be distinct enough in encfs filenaming scheme, right?) |
|
@imperative This fails at multithreading, which is a baseline assumption of encfs. |
|
The problem with any centralized database is that is basically explodes
once multiple encfs processes write to the same directory. So this would
kill the dropbox use case.
|
|
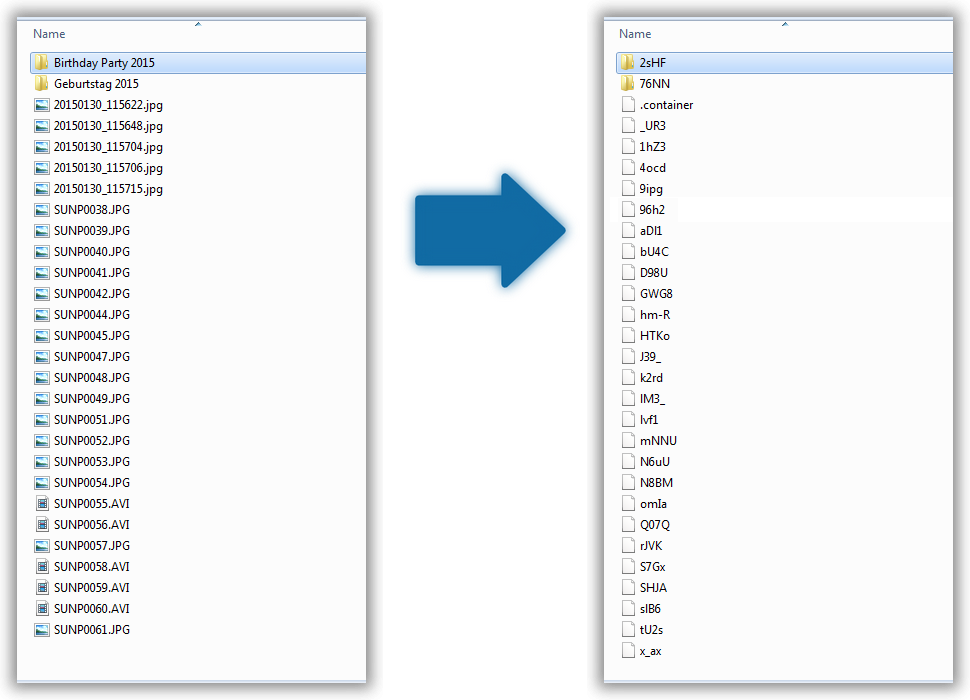
Can't we just make SHORT filenames? (not longer than original names) Look at how others handle this: CrococryptMirror for example - it encrypts every filename into 4 symbol filename (which is in 99% times shorter than the original) Environment
DescriptionEven with an option to have shortest possible encrypted filenames - stream - those are still longer than originals, i mean usually twice as long, eg: that's not really the problem, the real problem comes with folders and subfolders and subfolders inside subfolders... few folders placed in each other easily reach the filesystem max-length for name, filesystem have problems with it, programs have problems with it, cloud-storage have problems with it.. just problems we have. Expected behavior vs. actual behaviorwe should have an option for kitchen-level user filename protection which is not null but won't be longer than original something like: to not put the original key in danger by this (or however filename encryption is done), another key(password?) could be used, we need SOMETHING to not have problems with name-lengths of files... |
|
@Owyn See that new |
|
@fulldecent ok, but what about just some simply filename encoding? Like just XOR encryption or something which wouldn't make filenames longer, I know it's not military-level defense, but I just want things to work and not break cause of path-length limit. It's not necessary to use whole key for this, just a part of it or something derived to not risk it, so even if filenames get cracked - contents won't - a weak encryption is much more better for filenames than no encryption at all as it is now the only possible way to use encfs for many use-cases including mine. |
|
I'm hitting this issue. I'm saving my bitcoin wallet in encfs. Any solutions to this? |
|
Nothing yet in encfs. If you want long file names, you have two options:
|
|
For the windows users: I think (but untested) that this is resolved in newest Windows 10 with this fix: https://www.howtogeek.com/266621/how-to-make-windows-10-accept-file-paths-over-260-characters/ Maybe somebody can confirm? See also jetwhiz#63 |
|
This is to confirm this challenge is still present with EncFS 1.9.5 Using:
|
|
This issue is definitely something that produces problems when using encfs in conjunction with nextcloud, as that also has issues with longer filenames. |
I was going to comment something similar. There are length preserving encryption modes that are quite secure (xts, adiantum, hctr2). But the main length increasing step is converting the binary encrypted data to base64. Without that, the encrypted file names would contain random binary data, or at least random rare unicode characters, which is probably going to cause more problems than the current length limitations. |
Long filenames can exceed the filesystem limits after encryption & encoding. An alternative is to store filenames as file contents.
Just to revisit the current design, it is like this:
[ plain text filename ] --- encryption ---> [ encrypted blob ] --- base64 ---> [ encrypted filename ]
[ plain text filename ] --- encryption ---> [ encrypted blob ] --- sha256 --- hexdump ---> [ filename hash ]
The file would be called
longfn.[ filename hash ]and there is a second file,
longfn.[ filename hash ].fullnamethat stores the "encrypted blob".
I think this is the way to go. Build it into encfs instead of creating an external filesystem. This would be difficult to test and use and hence error prone and fragile.
The construction using the sha256 hash makes sure file lookup is efficient even for long file names. There should be no performance impact for directories not containing long file names. Each long file name in a folder will hit readdir performance with the penalty of reading the
longfn.[ filename hash ].fullname.Pull requests welcome!
The text was updated successfully, but these errors were encountered: